Alta disponibilidade com Debian Lenny + Heartbeat + DRBD8 + OCFS2 + MONIT + LVS
Neste artigo trataremos de como implementar alta disponibilidade tendo como exemplo um servidor web. Dá um pouco de trabalho, mas quando pronto e você testa a sua alta disponibilidade e vê tudo funcionando como você queria, dá um ar de satisfação tremendo.
[ Hits: 134.929 ]
Por: Douglas Q. dos Santos em 21/03/2010 | Blog: http://wiki.douglasqsantos.com.br

Um pouco de história
Quanto mais redundância existir, menores serão os SPOF (Single Point Of Failure), e menor será a probabilidade de interrupções no serviço. Até poucos anos atrás tais sistemas eram muito dispendiosos e tem-se vindo a intensificar uma procura em soluções alternativas. Surgem então os sistemas construídos com hardware acessível (clusters), altamente escaláveis e de custo mínimo. A figura 1 ilustra a configuração típica de um sistema de alta disponibilidade dual-node.
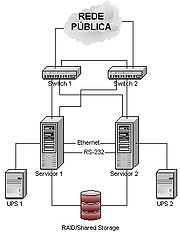
A tabela 1 ilustra um dos termos de comparação geralmente utilizado na avaliação de soluções HA: níveis de disponibilidade segundo tempos de indisponibilidade (downtime). Excluídos desta tabela, os tempos de downtime estimados (geralmente para manutenção ou reconfiguração dos sistemas) são alheios às soluções e muito variáveis.
Tabela 1 - Níveis de alta disponibilidade
Disponibilidade (%) Downtime/ano Downtime/mês 95% 18 dias 6:00:00 1 dias 12:00:00 96% 14 dias 14:24:00 1 dias 4:48:00 97% 10 dias 22:48:00 0 dias 21:36:00 98% 7 dias 7:12:00 0 dias 14:24:00 99% 3 dias 15:36:00 0 dias 7:12:00 99,9% 0 dias 8:45:35.99 0 dias 0:43:11.99 99,99% 0 dias 0:52:33.60 0 dias 0:04:19.20 99,999% 0 dias 0:05:15.36 0 dias 0:00:25.92Geralmente, quanto maior a disponibilidade, maior a redundância e custo das soluções: tudo depende do tipo de serviço que se pretende disponibilizar. Por exemplo, um operador de telecomunicações quererá certamente o mais elevado a fim de poder garantir um elevado nível de disponibilidade, sob pena de perder os seus clientes caso o sistema sofra falhas constantemente. No entanto, uma empresa com horário de trabalho normal poderá considerar que 90% de disponibilidade serão suficientes. É de salientar que o nível de disponibilidade mensal não é o mesmo que o anual. Efetivamente, para se obter um nível de disponibilidade mensal de 97%, é necessário que o nível anual seja aproximadamente de 99,75%. A tolerância a falhas consiste, basicamente, em ter hardware redundante que entra em funcionamento automaticamente após a detecção de falha do hardware principal. Independentemente da solução adotada, existem sempre dois parâmetros que possibilitam mensurar o grau de tolerância a falhas que são o MTBF - Mean Time Between Failures - (tempo médio entre falhas) e o MTTR - Mean Time To Repair - tempo médio de recuperação, que é o espaço de tempo (médio) que decorre entre a ocorrência da falha e a total recuperação do sistema ao seu estado operacional. A disponibilidade de um sistema pode ser calculada pela fórmula:
Disponibilidade = MTBF / (MTBF + MTTR)
Fonte: http://pt.wikipedia.org/wiki/Disponibilidade
Clusters de alta disponibilidade
Em vez de montar um único servidor com componentes redundantes, existe também a opção de usar um cluster de alta disponibilidade (chamado de "high-availability cluster" ou "failover cluster"), onde são usados dois servidores completos, onde a única função do segundo servidor é assumir a posição do primeiro em caso de falhas (modo chamado de ativo/passivo), diferente de um cluster com balanceamento de carga, onde os servidores dividem as requisições (ativo/ativo).Existem diversas soluções para clusters de alta disponibilidade. Entre as soluções abertas, uma das mais usadas é o projeto Linux-HA (High-Availability Linux, disponível no http://www.linux-ha.org), que desenvolve o Heartbeat, um daemon responsável por monitorar o status dos servidores do cluster e permitir que o segundo servidor assuma as funções do primeiro em caso de pane.
Cada um dos servidores possui pelo menos duas placas de rede, o que permite que eles sejam simultaneamente ligados à rede e ligados entre si através de um cabo crossover ou de um switch dedicado. A conexão interna é usada pelo Heartbeat para as funções de monitoramento e sincronismo dos processos, de forma que o segundo servidor possa assumir imediatamente a função do primeiro quando necessário, assumindo o endereço IP anteriormente usado por ele.
É comum também o uso de uma terceira interface de rede em cada servidor (ligada a um switch separado), destinada a oferecer uma conexão de backup com a rede. Isso permite eliminar mais um possível ponto de falha, afinal, de nada adianta ter servidores redundantes se o switch que os liga à rede parar de funcionar. :)
Em geral, o Heartbeat é usado em conjunto com o Drbd, que assume a função de manter os HDs dos dois servidores sincronizados, como uma espécie de RAID 1 via rede. Ao usar o Drbd, o HD do segundo servidor assume o papel de unidade secundária e é atualizado em relação ao do primeiro em tempo real. Quando o primeiro servidor pára, a unidade de armazenamento do segundo servidor passa a ser usada como unidade primária. Quando o servidor principal retorna, o HD é sincronizado em relação ao secundário e só então ele reassume suas funções.
Outra opção é utilizar uma SAN (veja a seguir) para que os dois servidores compartilhem a mesma unidade de armazenamento. Nesse caso, não é necessário manter o sincronismo, já que os dados são armazenados em uma unidade comum aos dois servidores.
Como pode ver, adicionar componentes redundantes, sejam fontes, HDs ou servidores adicionais aumentam consideravelmente os custos. A principal questão é avaliar se o prejuízo de ter o servidor fora do ar por algumas horas ou dias durante as manutenções, acidentes e imprevistos em geral é maior ou menor do que o investimento necessário.
Um pequeno servidor de rede local, que atende a meia dúzia de usuários em um pequeno escritório dificilmente precisaria de redundância, mas um servidor de missão-crítica (como no caso de um banco) com certeza precisa. Cada nível de redundância adiciona um certo valor ao custo dos servidores, mas reduz em certa proporção o tempo de downtime.
A disponibilidade do servidor é genericamente medida em "noves". Um nove indica uma disponibilidade de 90%, ou seja, uma situação em que o servidor fica fora do ar até 10% do tempo (imagine o caso de uma máquina instável, que precisa ser freqüentemente reiniciada, por exemplo), o que não é admissível na maioria das situações.
Com dois noves temos um servidor que fica disponível 99%, o que seria uma boa marca para um servidor "comum", sem recursos de redundância.
Por outro lado, uma disponibilidade de 99% significa que o servidor pode ficar fora do ar por até 7 horas e 18 minutos por mês (incluindo todas as manutenções, quedas de energia, operações de backup que tornem necessário parar os serviços e assim por diante), o que é tolerável no caso de uma rede local, ou no caso de um servidor que hospeda um site fora da área de comércio eletrônico, mas ainda não é adequado para operações de missão crítica.
Para adicionar mais um nove, atingindo 99.9% de disponibilidade (o famoso "three nines"), não é possível mais contar apenas com a sorte. É necessário começar a pensar nos possíveis pontos de falha e começar a adicionar recursos de redundância. Entram em cena as fontes redundantes, o uso de uma controladora RAID com suporte a hot-swap, uso de um nobreak com boa autonomia para todo o equipamento de rede, de forma que o servidor continue disponível mesmo durante as quedas de luz, e assim por diante. Afinal, 99.9% de disponibilidade significa que o servidor não fica fora do ar por mais de 43 minutos por mês.
No caso de servidores de missão crítica, qualquer interrupção no serviço pode representar um grande prejuízo, como no caso de instituições financeiras e grandes sites de comércio eletrônico. Passa então a fazer sentido investir no uso de um cluster de alta disponibilidade e em links redundantes, de forma a tentar atingir 99.99% de disponibilidade. Esta marca é difícil de atingir, pois significa que o servidor não deve ficar mais do que 4 minutos e meio (em média) fora do ar por mês, incluindo aí tudo o que possa dar errado.
Como sempre, não existe uma fórmula mágica para calcular o ponto ideal (é justamente por isso que existem consultores e analistas), mas é sempre prudente ter pelo menos um nível mínimo de redundância, nem que seja apenas um backup atualizado, que permita restaurar o servidor (usando outra máquina) caso alguma tragédia aconteça.
Referência: http://www.gdhpress.com.br/servidores/leia/index.php?p=cap14-3
Este artigo cobre como implementar a alta disponibilidade, ela pode ser aplicada a vários tipos de serviços.
Heartbeat funciona como gestor do cluster e dos seus recursos. Como o nome indica, a sinalização da presença (ou ausência) de contato com os nodos do cluster faz-se mediante o envio de pequenos pacotes (heartbeats, batimentos cardíacos) dirigidos a todos os nodos do cluster, cuja confirmação de recepção por parte de cada nodo indica o estado desse nodo.
Fonte: http://pt.wikipedia.org/wiki/Linux-HA
DBRD é a acrônimo para o nome inglês Distributed Replicated Block Device. O DRBD consiste num módulo para o núcleo Linux que, juntamente com alguns scripts, oferece um dispositivo de bloco projetado para disponibilizar dispositivos de armazenamento distribuídos, geralmente utilizado em clusters de alta disponibilidade. Isto é feito espelhando conjuntos de blocos via rede (dedicada). O DRBD funciona, portanto, como um sistema RAID baseado em rede.
Fonte: http://pt.wikipedia.org/wiki/Drbd
OCFS2 é um sistema de arquivos de cluster para Linux capaz de fornecer tanto de alto desempenho quanto alta disponibilidade.
Uma vez que fornece a semântica do sistema de arquivos local, ele pode ser usado com qualquer aplicação. Como cluster de aplicações sensíveis pode fazer uso de I/O paralelo para um melhor desempenho e fornecer um failover de configuração para aumentar a sua disponibilidade.
Além de ser usado com o Oracle Real Application Cluster de banco de dados do produto, OCFS2 está atualmente em uso para fornecer servidores de web escaláveis e servidores de arquivo, bem como fail-over-mail e servidores para hospedagem de imagens da máquina virtual. E pode ser utilizado para as mais diversas finalidades dentro de um sistema, não somente para os Bancos de dados, mas sim para qualquer partição na qual se deseje o acesso simultâneo de vários clientes.
Algumas das características notáveis do sistema de arquivos são:
- Tamanho variável de bloco
- Alocação flexível (extensões, escasso, as extensões não-escrita com a capacidade de furos)
- Journaling (ordenado e dados de write-back diário modos)
- Endian e Arquitetura Neutro (x86, x86_64, ia64 e ppc64)
- In-built Clusterstack com um Distributed Lock Manager Suporte para Buffered, Direct, Asynchronous, Splice e Memory Mapped I / Os
- Cluster Ferramentas de conhecimento (mkfs, fsck, tunefs etc)
Fonte: http://oss.oracle.com/projects/ocfs2
Monit é um utilitário de código aberto para gerenciamento e monitoramento, processos, arquivos, diretórios e arquivos em um sistema UNIX.
Monit efetua manutenção e reparo automático e pode executar ações significativas em situações de erro.
O que pode fazer o Monit?
Monit pode iniciar um processo se não funcionar, reiniciar um processo se ele não responder e interromper um processo, se ele usa recursos demais. Você pode usar Monit para monitorar arquivos, diretórios e arquivos para mudanças, como alterações carimbo do tempo, alterações ou mudanças de verificação de tamanho. Você também pode controlar máquinas remotas; Monit pode executar ping um host remoto e pode verificar conexões TCP / IP e porta do servidor. Monit é controlado através de um arquivo de controle baseados em um formato livre, sintaxe token-orientado.
Os logs do Monit podem ser para o syslog ou ao seu próprio arquivo de log e notificá-lo sobre as condições de erro e status de cobrança por via de alerta customizável.
Fonte: http://mmonit.com/monit/
LVS Linux Virtual Server (LVS) é uma solução de balanceamento de carga avançada para sistemas Linux. É um projeto Open Source começado por Wensong Zhang em maio de 1998. A missão do projeto é construir um servidor de alto desempenho e altamente disponível para Linux usando a tecnologia de clustering, que fornece altos níveis de escalabilidade, confiabilidade e usabilidade.
O trabalho principal do projeto de LVS deve agora desenvolver o software de balanceamento de carga avançado de IP (IPVS), o software de balanceamento de carga a nível aplicativo (KTCPVS) e componentes de gerenciamento de cluster.
IPVS: é um software balanceador de carga avançado do IP executado dentro do Linux. O código de IPVS era já incluído no núcleo padrão 2.4 e 2.6 de Linux.
KTCPVS: executa a carga do nível de aplicação que balança dentro do Linux, atualmente sob desenvolvimento.
Os usuários podem usar as soluções de LVS para construir serviços de rede altamente escaláveis e altamente disponíveis, tais como o serviço de mídia, serviço de email. Os meios prestam serviços de manutenção e serviços de VoIP, e integram serviços de rede escaláveis em aplicações de confiança em grande escala do e-comércio ou do e-governo.
As soluções de LVS têm sido desdobradas já em muitas aplicações reais durante todo o mundo.
Fonte: http://pt.wikipedia.org/wiki/LVS
Para mais informações a respeito dessas ferramentas podem ser consultados os links abaixo.
Essas ferramentas são ótimas para garantir a alta disponibilidade dos nossos servidores como pode ser visto.
A implementação é um pouco trabalhosa na primeira vez, mas com o passar do tempo isso fica bem fácil que você pode até criar um script para fazer tudo isso.
Só não vão achando que este artigo vai deixar você um expert em alta disponibilidade, eu só vou dar o caminho das pedras e vocês tem que ir seguindo em diante.
Dependendo da distribuição GNU/Linux isso pode se tornar mais fácil ou mais difícil em questão de trabalho, fora isso é aplicado a qualquer distro. No momento estou fazendo esta implementação em FreeBSD, assim que terminar vou publicar as diferenças na implementação.
Então chega de história, só os oriento a pesquisarem mais sobre o assunto e fazerem muitos testes antes de colocarem em produção por que só com o tempo para ir se familiarizando com os possíveis erros.
Vamos começar!
2. Nosso ambiente de implementação
3. Preparação do ambiente
4. Instalação e configuração do Heartbeat
5. Gerenciando o Heartbeat com Haclient
6. Instalação e configuração do DRBD8 e OCFS2
7. LVS
8. Instalação e configuração do Monit
Bonding para Heartbeat + Bonding para DRBD + OCFS2 + Debian Squeeze
Apache em chroot + MySQL + PHP + mod_security + mod_evasive + vsftpd + Fail2ban + Debian Squeeze
Bind9 slave em chroot no Debian Lenny
Debian + Postfix + MySQL + PostfixAdmin + MailScanner + Webmail + Quotas
Claws Mail: o cliente de correio eletrônico que morde!
Implementando auto-resposta utilizando o Exim
Os atuais MDAs e as linguagens de filtragem de e-mail (parte 1 - Procmail)
Webmail Roundcubemail em PHP4/PHP5 com skins, LDAP e extras
RoundCubeMail - Praticidade e bom gosto
Muito bom, essa semana mesmo preciso implementar um ambiente desses e talvez seu artigo possa me ajudar.
Parabéns!
[ ]'s
Luiz
É, podem seguir linha a linha desse artigo que funciona, implantei aqui no meu trabalho e foi total sucesso, o Douglas fez um excelente trabalho.
muito obrigado.!!!!
Vou fazer meu TCC sobre cluster, esse artigo será bastante útil e vou usar como referência no meu trabalho.
Parabéns Douglas, e obrigado pelas dicas que você já meu deu até hoje.
Um abraço.
Obrigado pelos comentários.
Espero continuar contribuindo sempre.
Douglas.
Douglas,
Parabéns pelo excelente artigo, vc foi muito didático e me ajudou muito na implantação de uma solução similar em um cliente.
Seu artigo esta muito bem escrito e direto.
Estou tentando adaptar essa solução para um servidor samba com controlador de dominio o processo está de vento em popa.
Mas ficaram três dúvidas :
Primeiro - Utilizo o Debian Lenny atualizado, mas o parâmetro que foi indicado no FSTAB ( _netdev ) não esta seno reconhecino na inicialização da máquina, consequentemente ele não monta o filesystem OCFS2 automaticamente.
Segundo - No início do seu artigo deu a entender que precisava-se de 2 placas de rede em cada máquina mas ao implementar o mesmo não encontrei referência alguma da configuração dessa segunda placa.
Terceiro com relação ao LVS achei a idéia muito boa mas é realmente necessário a adição de uma terceira máquina no serviço ? Poderia-se colocar o LVS em uma das máquinas do cluster?
Mais uma vez parabéns pelo excelente artigo continue assim nossa comunidade só tem a ganhar ....
Viva a Liberdade
Viva o Linux
Uma abraço
Luiz Xavier .:
Boa Tarde Douglas !!!
Das minhas dúvidas eu já consegui resolver uma :
a linha do FSTAB referente a montagem do OCFS2 está errada o correto segue abaixo :
/dev/drbd1 /ocfs2 ocfs2 _netdev,defaults 0 0
Espero ter ajudado ;)
Atenciosamente
Luiz Xavier.:
Viva a Liberdade !!!
Viva o Linux !!!
Boa Tarde a todos ....
Mais uma vez gostaria de deixar minhas impressões com as pessoas que verem esse tópico.
Nosso colaborador Douglas está de parabéns .
Segui seu tutorial e fiz alguns ajustes e hoje sou um feliz próprietário de um cluster total rodanda Samba PDC, Squid Autenticado e OpenVpn.
Parabéns mais uma vez
Continue sempre assim ...
Viva a Liberdade !!!
Viva o Linux !!!!
Luiz Xavier .:
Olá...
Primeiramente parabéns pelo artigo. Será de grande valia!!!
Tenho um problema: na hora de executar o Heartbeat em modo gráfico (heartbeat-2-gui) dá erro e nao abre. Tentei instalar em outra máquina e utilizar o putty e colocar o comando, mas ele nem abre. Se eu digitar o comando, da erro também. Alguem passou por isso, ou sabe como ontornar isso?
Situação:
Instalação em duas máquinas Debian/Lenny atualizadas, somente modo texto.
Erro:
debian1:~# /usr/lib/heartbeat-gui/haclient.py &
[1] 2372
debian1:~# /var/lib/python-support/python2.5/gtk-2.0/gtk/__init__.py:72: GtkWarning: could not open display
warnings.warn(str(e), _gtk.Warning)
/usr/lib/heartbeat-gui/haclient.py:1964: Warning: invalid (NULL) pointer instance
win_widget = gtk.Window()
/usr/lib/heartbeat-gui/haclient.py:1964: Warning: g_signal_connect_data: assertion `G_TYPE_CHECK_INSTANCE (instance)' failed
win_widget = gtk.Window()
/usr/lib/heartbeat-gui/haclient.py:2077: Warning: invalid (NULL) pointer instance
menubar = uimanager.get_widget('/menubar')
/usr/lib/heartbeat-gui/haclient.py:2077: Warning: g_signal_connect_data: assertion `G_TYPE_CHECK_INSTANCE (instance)' failed
menubar = uimanager.get_widget('/menubar')
/usr/lib/heartbeat-gui/haclient.py:2077: GtkWarning: gtk_settings_get_for_screen: assertion `GDK_IS_SCREEN (screen)' failed
menubar = uimanager.get_widget('/menubar')
/usr/lib/heartbeat-gui/haclient.py:2077: Warning: g_object_get: assertion `G_IS_OBJECT (object)' failed
menubar = uimanager.get_widget('/menubar')
/usr/lib/heartbeat-gui/haclient.py:2077: Warning: value "TRUE" of type `gboolean' is invalid or out of range for property `visible' of type `gboolean'
menubar = uimanager.get_widget('/menubar')
/usr/lib/heartbeat-gui/haclient.py:2084: Warning: invalid (NULL) pointer instance
glade = gtk.glade.XML(UI_FILE, "mainwin_main", "haclient")
/usr/lib/heartbeat-gui/haclient.py:2084: Warning: g_signal_connect_data: assertion `G_TYPE_CHECK_INSTANCE (instance)' failed
glade = gtk.glade.XML(UI_FILE, "mainwin_main", "haclient")
/usr/lib/heartbeat-gui/haclient.py:2084: GtkWarning: gtk_settings_get_for_screen: assertion `GDK_IS_SCREEN (screen)' failed
glade = gtk.glade.XML(UI_FILE, "mainwin_main", "haclient")
/usr/lib/heartbeat-gui/haclient.py:2092: GtkWarning: Screen for GtkWindow not set; you must always set
a screen for a GtkWindow before using the window
win_widget.show_all()
/usr/lib/heartbeat-gui/haclient.py:2092: GtkWarning: gtk_settings_get_for_screen: assertion `GDK_IS_SCREEN (screen)' failed
win_widget.show_all()
/usr/lib/heartbeat-gui/haclient.py:2092: Warning: g_object_get: assertion `G_IS_OBJECT (object)' failed
win_widget.show_all()
/usr/lib/heartbeat-gui/haclient.py:2092: GtkWarning: gdk_pango_context_get_for_screen: assertion `GDK_IS_SCREEN (screen)' failed
win_widget.show_all()
/usr/lib/heartbeat-gui/haclient.py:2092: PangoWarning: pango_context_set_font_description: assertion `context != NULL' failed
win_widget.show_all()
/usr/lib/heartbeat-gui/haclient.py:2092: PangoWarning: pango_context_set_base_dir: assertion `context != NULL' failed
win_widget.show_all()
/usr/lib/heartbeat-gui/haclient.py:2092: PangoWarning: pango_context_set_language: assertion `context != NULL' failed
win_widget.show_all()
/usr/lib/heartbeat-gui/haclient.py:2092: PangoWarning: pango_layout_new: assertion `context != NULL' failed
win_widget.show_all()
/usr/lib/heartbeat-gui/haclient.py:2092: PangoWarning: pango_layout_set_text: assertion `layout != NULL' failed
win_widget.show_all()
/usr/lib/heartbeat-gui/haclient.py:2092: PangoWarning: pango_layout_set_attributes: assertion `layout != NULL' failed
win_widget.show_all()
/usr/lib/heartbeat-gui/haclient.py:2092: PangoWarning: pango_layout_set_alignment: assertion `layout != NULL' failed
win_widget.show_all()
/usr/lib/heartbeat-gui/haclient.py:2092: PangoWarning: pango_layout_set_ellipsize: assertion `PANGO_IS_LAYOUT (layout)' failed
win_widget.show_all()
/usr/lib/heartbeat-gui/haclient.py:2092: PangoWarning: pango_layout_set_single_paragraph_mode: assertion `PANGO_IS_LAYOUT (layout)' failed
win_widget.show_all()
/usr/lib/heartbeat-gui/haclient.py:2092: PangoWarning: pango_layout_set_width: assertion `layout != NULL' failed
win_widget.show_all()
/usr/lib/heartbeat-gui/haclient.py:2092: PangoWarning: pango_layout_get_extents: assertion `layout != NULL' failed
win_widget.show_all()
/usr/lib/heartbeat-gui/haclient.py:2092: PangoWarning: pango_layout_get_pixel_extents: assertion `PANGO_IS_LAYOUT (layout)' failed
win_widget.show_all()
/usr/lib/heartbeat-gui/haclient.py:2092: Warning: g_object_unref: assertion `G_IS_OBJECT (object)' failed
win_widget.show_all()
/usr/lib/heartbeat-gui/haclient.py:2092: GtkWarning: gtk_icon_size_lookup_for_settings: assertion `GTK_IS_SETTINGS (settings)' failed
win_widget.show_all()
/usr/lib/heartbeat-gui/haclient.py:2092: GtkWarning: /build/buildd-gtk+2.0_2.12.12-1~lenny2-i386-2RfKoO/gtk+2.0-2.12.12/gtk/gtkstyle.c:2123: invalid icon size '3'
win_widget.show_all()
/usr/lib/heartbeat-gui/haclient.py:2092: GtkWarning: gtk_style_render_icon: assertion `pixbuf != NULL' failed
win_widget.show_all()
/usr/lib/heartbeat-gui/haclient.py:2092: GtkWarning: Failed to render icon
win_widget.show_all()
/usr/lib/heartbeat-gui/haclient.py:2092: Warning: g_object_ref: assertion `G_IS_OBJECT (object)' failed
win_widget.show_all()
/usr/lib/heartbeat-gui/haclient.py:2092: PangoWarning: pango_context_get_language: assertion `context != NULL' failed
win_widget.show_all()
/usr/lib/heartbeat-gui/haclient.py:2092: PangoWarning: pango_context_get_metrics: assertion `PANGO_IS_CONTEXT (context)' failed
win_widget.show_all()
/usr/lib/heartbeat-gui/haclient.py:2092: PangoWarning: pango_font_metrics_get_approximate_char_width: assertion `metrics != NULL' failed
win_widget.show_all()
/usr/lib/heartbeat-gui/haclient.py:2092: PangoWarning: pango_layout_get_context: assertion `layout != NULL' failed
win_widget.show_all()
/usr/lib/heartbeat-gui/haclient.py:2092: PangoWarning: pango_font_metrics_get_approximate_digit_width: assertion `metrics != NULL' failed
win_widget.show_all()
/usr/lib/heartbeat-gui/haclient.py:2092: PangoWarning: pango_font_metrics_get_ascent: assertion `metrics != NULL' failed
win_widget.show_all()
/usr/lib/heartbeat-gui/haclient.py:2092: PangoWarning: pango_font_metrics_get_descent: assertion `metrics != NULL' failed
win_widget.show_all()
/usr/lib/heartbeat-gui/haclient.py:2092: GtkWarning: gdk_screen_get_default_colormap: assertion `GDK_IS_SCREEN (screen)' failed
win_widget.show_all()
/usr/lib/heartbeat-gui/haclient.py:2092: GtkWarning: gdk_colormap_get_visual: assertion `GDK_IS_COLORMAP (colormap)' failed
win_widget.show_all()
/usr/lib/heartbeat-gui/haclient.py:2092: GtkWarning: gdk_screen_get_root_window: assertion `GDK_IS_SCREEN (screen)' failed
win_widget.show_all()
/usr/lib/heartbeat-gui/haclient.py:2092: GtkWarning: gdk_window_new: assertion `GDK_IS_WINDOW (parent)' failed
win_widget.show_all()
/usr/lib/heartbeat-gui/haclient.py:2092: GtkWarning: gdk_window_enable_synchronized_configure: assertion `GDK_IS_WINDOW (window)' failed
win_widget.show_all()
/usr/lib/heartbeat-gui/haclient.py:2092: GtkWarning: gdk_window_set_user_data: assertion `window != NULL' failed
win_widget.show_all()
/usr/lib/heartbeat-gui/haclient.py:2092: GtkWarning: gtk_style_attach: assertion `window != NULL' failed
win_widget.show_all()
/usr/lib/heartbeat-gui/haclient.py:2092: GtkWarning: gtk_style_set_background: assertion `GTK_IS_STYLE (style)' failed
win_widget.show_all()
/usr/lib/heartbeat-gui/haclient.py:2092: GtkWarning: gtk_paint_flat_box: assertion `GTK_IS_STYLE (style)' failed
win_widget.show_all()
/usr/lib/heartbeat-gui/haclient.py:2092: GtkWarning: gdk_window_set_accept_focus: assertion `GDK_IS_WINDOW (window)' failed
win_widget.show_all()
/usr/lib/heartbeat-gui/haclient.py:2092: GtkWarning: gdk_window_set_focus_on_map: assertion `GDK_IS_WINDOW (window)' failed
win_widget.show_all()
/usr/lib/heartbeat-gui/haclient.py:2092: GtkWarning: gdk_window_set_modal_hint: assertion `GDK_IS_WINDOW (window)' failed
win_widget.show_all()
/usr/lib/heartbeat-gui/haclient.py:2092: GtkWarning: gtk_window_realize_icon: assertion `widget->window != NULL' failed
win_widget.show_all()
/usr/lib/heartbeat-gui/haclient.py:2092: GtkWarning: gdk_window_set_geometry_hints: assertion `GDK_IS_WINDOW (window)' failed
win_widget.show_all()
/usr/lib/heartbeat-gui/haclient.py:2092: GtkWarning: gdk_window_invalidate_rect: assertion `window != NULL' failed
win_widget.show_all()
/usr/lib/heartbeat-gui/haclient.py:2092: GtkWarning: gdk_window_show: assertion `GDK_IS_WINDOW (window)' failed
win_widget.show_all()
/usr/lib/heartbeat-gui/haclient.py:2092: GtkWarning: gdk_window_get_events: assertion `GDK_IS_WINDOW (window)' failed
win_widget.show_all()
/usr/lib/heartbeat-gui/haclient.py:2092: GtkWarning: gdk_window_set_events: assertion `GDK_IS_WINDOW (window)' failed
win_widget.show_all()
/usr/lib/heartbeat-gui/haclient.py:2092: GtkWarning: gdk_screen_get_display: assertion `GDK_IS_SCREEN (screen)' failed
win_widget.show_all()
/usr/lib/heartbeat-gui/haclient.py:2092: GtkWarning: gdk_cursor_new_for_display: assertion `GDK_IS_DISPLAY (display)' failed
win_widget.show_all()
/usr/lib/heartbeat-gui/haclient.py:2092: GtkWarning: gdk_cursor_unref: assertion `cursor != NULL' failed
win_widget.show_all()
/usr/lib/heartbeat-gui/haclient.py:2092: GtkWarning: gdk_window_set_back_pixmap: assertion `GDK_IS_WINDOW (window)' failed
win_widget.show_all()
/usr/lib/heartbeat-gui/haclient.py:2092: GtkWarning: gdk_drawable_get_colormap: assertion `GDK_IS_DRAWABLE (drawable)' failed
win_widget.show_all()
/usr/lib/heartbeat-gui/haclient.py:2092: GtkWarning: gdk_window_set_background: assertion `GDK_IS_WINDOW (window)' failed
win_widget.show_all()
Bom dia.
Cara pela sua situação abaixo.
Situação:
Instalação em duas máquinas Debian/Lenny atualizadas, somente modo texto.
Não tem como você executar o haclient.
/usr/lib/heartbeat-gui/haclient.py &
para você poder exportar a tela eu comentei no tutorial que precisa de uma maquina com modo gráfico.
e dava para fazer a exportação da tela do haclient.py via putty em modo grafico.
nem precisa ser a que tenha o servidor mais pelo meno um cliente pois a tela que vc esta querendo exportar é feita em python e necessita de algumas bibliotecas de modo grafico X.
para resolver o seu problema instale uma maquina com o modo grafico so para voce gerenciar o seu cluster e deixe os seus server somente com o modo texto para não ficar enchendo o seu server de aplicativos e bibliotecas X.
Douglas.
Bom dia Douglas,
Já tinha o heartbeat instalado nos servidores(Debian 5), mas com a versão 1, instalei o heartbeat-gui nos servidores (locais) e usei o comando "/usr/lib/heartbeat-gui/haclient.py &".
Acesso os servidores com o ssh com X11 para usar a interface grafica da minha maquina local:
#ssh servidor -XY
Abri o Haclient normalmente:
Server 127.0.0.1
User Name hacluster
Password: em branco
Utilizo a senha que cadastrei mas não consigo conectar no servidor, tentei a conexão com o IP LAN do servidor mas gera o mesmo erro.
Tenho que especificar alguma porta?
Sabe o que pode estar ocorrendo?
Obs.: Não tenho firewall habilitado neste servidor e adicionei o user hacluster no grupo haclient(encontrei em um forum)
Obrigado e parabens!
Bom dia caro colega.
acho que vc esqueceu disso aqui.
Como na instalação do Heartbeat ele não pediu senha para o hacluster, temos que inserir uma para podemos conectar no Heartbeat.
# passwd hacluster
dai vc informa a senha e loga o hacliet.
Douglas
Boa noite a todos
Agradeço o artigo, está me ajudando bastante.
Porem ainda tenho um problema com o heartbeat.
Quando o host1 e host2 estão operando não consigo acessar o apache na rede, porem quando coloco qualquer um deles em standby o serviço funciona.
alguem pode me dar uma dica?
ops!
Já resolvi, era apenas um location para o mesmo serviço, ou seja, por engano setei um outro location qualquer com apache tbm, ai duplicou o serviço.
Tutorial simplesmente perfeito.
Está de parabéns.
Pessoal, estava seguindo esse tutorial, mas ai surgiu uma dúvida, onde gero essa senha ?
# vim /etc/ha.d/authkeys
# /etc/ha.d/authkeys
#Definir qual o método de autenticação.
auth 3
#Métodos de autenticação disponíveis
1 crc <--------------------------------------------------------------------
2 sha1 senha <----------------------------------------------------------
3 md5 senha <----------------------------------------------------------
Muito obrigado a todos, bom dia.
Olá Douglas,
O heartbeat só funciona com cabo crossover ligando os nodos?
Obrigado,
Felipe
Boa tarde.
Não, pode ser utilizado um cabo padrão de rede, o heartbeat somente vai garantir que um endereço ip seja compartilhado entre os servidores, ou vai monitorar um determinado serviço ou partição, mas o servidor pode ser montado como qualquer outro.
Boa noite a todos.
Fui seguindo o tutorial passo a passo porem adaptando ele para minha situação. Estou utilizando ja o debian wheezy, e não consigo instalar o heartbeat-gui....
Busco ele no apt-get e ele não encontra....o heartbeat instalado é a versão 3
Obrigado.
E ai fernando o que acontece é o seguinte o projeto do heartbeat e do corosync forão separados e foram descontinuadas algumas features.
da uma olhada nesse link aqui http://www.douglas.wiki.br/doku.php?id=corosync_pacemaker_lcmc_no_debian_squeeze
aqui eu fiz a implementação com o novo modelo a implementação do squeeze e do wheezy é para ser a mesma.
Patrocínio

Destaques
Artigos
A produção de áudio e vídeo no Linux e as distribuições dedicadas a esse fim
Criptografando sua Home com Gocryptfs para tristeza do meliante
A Involução do Linux e as Lambanças Desnecessárias desde o seu Lançamento
O Journal no Linux para a guarda e consulta de logs do sistema
A evolução do Linux e as mudanças que se fazem necessárias desde o seu lançamento
Dicas
Zen Kernel no Arch Linux (instalar e remover)
Como instalar e remover o kernel Liquorix
Fazendo o controle de Xbox 360 USB funcionar no One Piece Pirate Warriors 4 (Arch Linux/Steam)
Tópicos
Loop infinito em uma media ponderada. (3)
Não consigo publicar screenshots no Viva o Linux (2)
Top 10 do mês
-

Xerxes
1° lugar - 155.674 pts -

Fábio Berbert de Paula
2° lugar - 79.209 pts -

Buckminster
3° lugar - 48.010 pts -

Alberto Federman Neto.
4° lugar - 45.237 pts -

Alessandro de Oliveira Faria (A.K.A. CABELO)
5° lugar - 35.384 pts -

edps
6° lugar - 32.672 pts -

Sidnei Serra
7° lugar - 27.924 pts -

Mauricio Ferrari (LinuxProativo)
8° lugar - 25.417 pts -

Daniel Lara Souza
9° lugar - 24.008 pts -

Andre (pinduvoz)
10° lugar - 22.660 pts
Scripts
A maior comunidade GNU/Linux da América Latina! Artigos, dicas, tutoriais, fórum, scripts e muito mais. Ideal para quem busca auto-ajuda.
Site hospedado por: