Sistema lento? Encontrando a causa do problema
O que você faz quando recebe um alerta de que o seu sistema está lento ou sobrecarregado? Rastrear a causa da sobrecarga só leva algum tempo, alguma experiência e algumas ferramentas do GNU/Linux.

Introdução
Os principais motivos de uma lentidão no sistema são:
Vamos instalar as ferramentas necessárias para encontrar os causadores do problema.
Em sistemas Linux baseados em Debian:
# apt-get install iotop sysstat
Em sistemas Linux baseados em Red Hat:
# yum install iotop sysstat
uptime
18:30:35 up 365 days, 5:29, 2 users, load average: 1.37, 10.15, 8.10
No comando acima ele mostra que esse servidor foi ligado há 365 dias, 5 horas e 29 minutos, exatamente às 18:30:35. Possui 2 usuários conectados no servidor e o uso do CPU é 1.37 (média no último minuto), 10.15 (média dos últimos 5 minutos) e 8.10 (média dos últimos 15 minutos).
Para você entender melhor o "CPU Load", vamos analisar essa imagem: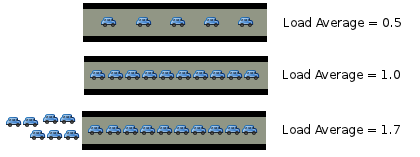
Caso você tenha um processador single core, o limite de load average sem ficar nenhum processo na fila é 1, se for quad core o limite é 4 e assim por diante.
Existe um comando mais completo, além de mostrar tudo que o uptime mostra, ele ainda exibe utilização das memórias e os processos. Esse comando é o top. Para quem quer um comando com uma formatação colorida, mais bonita e cheia de frescura, basta instalar o htop.
Para instalar o htop nos sistemas baseados em Debian, utilize o seguinte comando:
# apt-get install htop
Para instalar o htop nos sistemas baseados em Red Hat, utilize o seguinte comando:
# yum install htop
Vamos ver a saída do comando:
# top
top - 14:08:25 up 38 days, 8:02, 1 user, load average: 1.70, 1.77, 1.68
Tasks: 107 total, 3 running, 104 sleeping, 0 stopped, 0 zombie
Cpu(s): 11.4%us, 29.6%sy, 0.0%ni, 58.3%id, .7%wa, 0.0%hi, 0.0%si, 0.0%st
Mem: 1024176k total, 997408k used, 26768k free, 85520k buffers
Swap: 1004052k total, 4360k used, 999692k free, 286040k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
9463 mysql 16 0 686m 111m 3328 S 53 5.5 569:17.64 mysqld
18749 nagios 16 0 140m 134m 1868 S 12 6.6 1345:01 nagios2db_status
24636 nagios 17 0 34660 10m 712 S 8 0.5 1195:15 nagios
22442 nagios 24 0 6048 2024 1452 S 8 0.1 0:00.04 check_time.pl
Para verificar se o problema está na sobrecarga do CPU, vamos olhar a linha abaixo do comando top:
Cpu (s): 11,4%us, 29,6%sy, 0,0%ni, 58,3%id, 0,7%wa, 0,0%hi, 0,0%si, 0,0%st
Vou falar um pouco das principais siglas utilizadas pelo comando:
Resumindo: se você ver um percentual alto das colunas "%us" e "%sy", há uma boa chance do causador do problema ser vinculado à CPU.
A coluna "%CPU" diz o quanto cada processo está ocupando do(s) processador(es).
Você provavelmente verá duas coisas:
Sistemas multithreaded podem deixar incrivelmente sobrecarregada a CPU, simplesmente por gerar um grande número de threads em um sistema sem muitas CPUs. Se você gerar 20 threads em um sistema Single Core, você poderá ver um alto load average, embora não haja processos particulares que parecem amarrar o tempo de CPU (TIME+).
- Sobrecarga causada por CPU.
- Sobrecarga causada por problemas de memória insuficiente.
- Sobrecarga causada por problemas de I/O de discos ou partições.
Vamos instalar as ferramentas necessárias para encontrar os causadores do problema.
Em sistemas Linux baseados em Debian:
# apt-get install iotop sysstat
Em sistemas Linux baseados em Red Hat:
# yum install iotop sysstat
Problema causado pelo processador
O primeiro comando que eu sempre digito para ver o possível causador da lentidão do sistema é o uptime:uptime
18:30:35 up 365 days, 5:29, 2 users, load average: 1.37, 10.15, 8.10
No comando acima ele mostra que esse servidor foi ligado há 365 dias, 5 horas e 29 minutos, exatamente às 18:30:35. Possui 2 usuários conectados no servidor e o uso do CPU é 1.37 (média no último minuto), 10.15 (média dos últimos 5 minutos) e 8.10 (média dos últimos 15 minutos).
Para você entender melhor o "CPU Load", vamos analisar essa imagem:

- Se o load average é 1.7, sete tarefas ficam "em espera" enquanto as outras 10 estão "fluindo".
- Quando o load average é 1.0, note que todas as tarefas são executadas e nenhuma é colocada em espera.
- E, no primeiro caso, existe tempo de sobra para execução de outras tarefas...
Caso você tenha um processador single core, o limite de load average sem ficar nenhum processo na fila é 1, se for quad core o limite é 4 e assim por diante.
Existe um comando mais completo, além de mostrar tudo que o uptime mostra, ele ainda exibe utilização das memórias e os processos. Esse comando é o top. Para quem quer um comando com uma formatação colorida, mais bonita e cheia de frescura, basta instalar o htop.
Para instalar o htop nos sistemas baseados em Debian, utilize o seguinte comando:
# apt-get install htop
Para instalar o htop nos sistemas baseados em Red Hat, utilize o seguinte comando:
# yum install htop
Vamos ver a saída do comando:
# top
top - 14:08:25 up 38 days, 8:02, 1 user, load average: 1.70, 1.77, 1.68
Tasks: 107 total, 3 running, 104 sleeping, 0 stopped, 0 zombie
Cpu(s): 11.4%us, 29.6%sy, 0.0%ni, 58.3%id, .7%wa, 0.0%hi, 0.0%si, 0.0%st
Mem: 1024176k total, 997408k used, 26768k free, 85520k buffers
Swap: 1004052k total, 4360k used, 999692k free, 286040k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
9463 mysql 16 0 686m 111m 3328 S 53 5.5 569:17.64 mysqld
18749 nagios 16 0 140m 134m 1868 S 12 6.6 1345:01 nagios2db_status
24636 nagios 17 0 34660 10m 712 S 8 0.5 1195:15 nagios
22442 nagios 24 0 6048 2024 1452 S 8 0.1 0:00.04 check_time.pl
Para verificar se o problema está na sobrecarga do CPU, vamos olhar a linha abaixo do comando top:
Cpu (s): 11,4%us, 29,6%sy, 0,0%ni, 58,3%id, 0,7%wa, 0,0%hi, 0,0%si, 0,0%st
Vou falar um pouco das principais siglas utilizadas pelo comando:
- us - tempo de CPU gasto com usuário. Na maioria das vezes, quando você tem a carga no limite da CPU, é devido a um processo executado por um usuário no sistema, como o Apache, MySQL ou talvez um Shell Script. Se esta percentagem é elevada, um processo de utilizador tais como aqueles citados podem ser os causadores da lentidão.
- sy - tempo de CPU gasto com sistema. É a percentagem da CPU utilizada pelo kernel e outros processos do sistema.
- id - tempo de CPU ociosa do sistema. Esta é a percentagem do tempo em que a CPU está ociosa. Quanto maior o número aqui, melhor! Na verdade, se você vê realmente um alto tempo ocioso da CPU, podemos descartar que o problema de lentidão seja a CPU.
- wa - tempo de espera do I/O. O valor de espera do I/O conta a percentagem de tempo que o CPU está gastando à espera de I/O. Se este valor é alto, é provável que o problema não seja vinculada à CPU, mas provavelmente seja causado pela memória RAM ou pelo I/O de disco.
Resumindo: se você ver um percentual alto das colunas "%us" e "%sy", há uma boa chance do causador do problema ser vinculado à CPU.
A coluna "%CPU" diz o quanto cada processo está ocupando do(s) processador(es).
Você provavelmente verá duas coisas:
- Um único processo com 99% de uso do(s) processador(es).
- Vários pequenos processos lutando pelo tempo de CPU (%TIME+).
Sistemas multithreaded podem deixar incrivelmente sobrecarregada a CPU, simplesmente por gerar um grande número de threads em um sistema sem muitas CPUs. Se você gerar 20 threads em um sistema Single Core, você poderá ver um alto load average, embora não haja processos particulares que parecem amarrar o tempo de CPU (TIME+).
Parabéns , muito bom o Artigo