Varnish: Uma camada de velocidade
O objetivo deste trabalho é apresentar ao leitor a ferramenta de proxy reverso Varnish, mostrar suas principais características e averiguar seu desempenho através de testes de benchmark. Nesta última fase foram feitos testes comparativos entre o Varnish e o Squid, em que ficou patente do desempenho superior do Varnish em todos os testes executados.
[ Hits: 73.094 ]
Por: Perfil removido em 10/05/2010

Introdução
O fato é que, a partir desse evento, a Internet sofreu um novo boom de aplicações para oferecer todo tipo de serviço colaborativo. Aplicações antes quase estáticas ganharam vida, disparando requisições Ajax para todo o planeta, solicitando mais interação e colaboração.
Do outro lado da linha, servidores Web se viram abarrotados de requisições ininterruptas, solicitando atualizações de caixa de email, os mais novos comentários, a cotação das ações. Serviços Web como blogs, fóruns e wikis se tornaram aplicações completas e pesadas que, de um lado, permitiam a um completo leigo gerir suas postagens na Web, mas, de outro, oneravam severamente os recursos do servidor.
Questões como escalabilidade e disponibilidade se tornam problemas complicados e urgentes. Okama [2] cita que normalmente a cada requisição GET no protocolo HTTP 1.1 é necessário se fazer vários acessos a banco de dados e executar muitos códigos em alguma linguagem de script. Assim que a requisição é entregue, todo esse trabalho é jogado fora e recomeçado na próxima requisição.
Soluções de cache e aceleração de processamento para os mais diversos tipos de aplicação se tornaram o assunto da vez. O Grupo Brasileiro de Usuários FreeBSD - FUG-BR [3] alerta que embora existam diversos sistemas de cache para linguagens especificas como o PHP, esses aceleradores não são de propósito geral, não funcionam para Zope-Plone, Java ou ASP em um mesmo momento. Para esses casos, FUG-BR aponta como solução adequada a utilização de sistemas de proxy reversos.
Tipicamente, um serviço de proxy é utilizado para compartilhar serviços de internet através de varias máquinas. Todas as requisições Web dos clientes são direcionadas para esse serviço, para que este decida se deve responder à requisição com algum objeto de seu cache ou se deverá enviá-la para algum servidor na Internet.
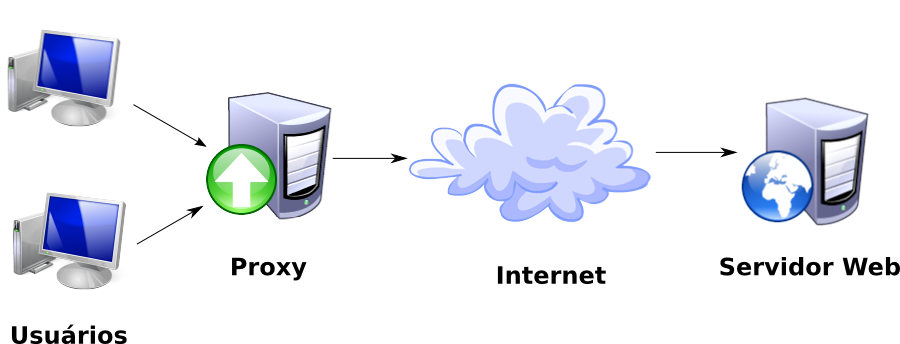
Diagrama de funcionamento do proxy
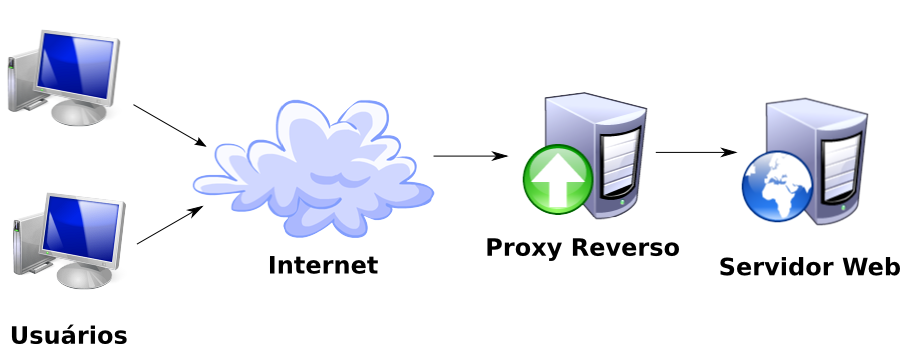
Diagrama de funcionamento do proxy reverso
Numa análise a respeito destas soluções, Poul-Henning Kamp [5] aponta que o Squid apresenta diversos problemas arquiteturais. Em 1975, quando começou a ser desenvolvido, computadores eram formados basicamente de CPU, armazenamento interno e armazenamento externo, mas atualmente esta definição já não é cabível. Computadores atuais são formados por um número indefinido de cores ligados a um número variável de sistemas de cache e barramentos para dispositivos de armazenamento virtualizados.
O Squid possui duas configurações principais, que dizem respeito a quanta memória volátil e quanto espaço em disco o proxy deverá utilizar. Kamp [6] descreve diversos problemas de desempenho que o Squid apresenta quando tenta controlar o gerenciamento da memória de forma independente do Kernel.
Um dos maiores problemas citados se dá quando o Squid armazena objetos na memória volátil e, depois de algum tempo inativos, são jogados em disco pelo Kernel. Quando o Squid torna a requisitá-los, faz-se necessário que o Kernel retorne o objeto para a memória volátil e somente depois libere os objetos para o Squid, causando assim um grande retrabalho.
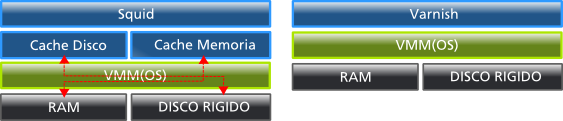
Arquiteturas do Squid e do Varnish
Segundo FUG-BR [3], foi a partir desta análise que, em meados de 2006, a VG Multimédia se juntou ao Grupo de Usuários Unix da Noruega para financiar a construção de um novo sistema de proxy que conseguisse ter um desempenho e arquitetura melhores que a do Squid. Mas a maior aquisição do projeto certamente foi a de Poul-Henning Kamp como arquiteto e codificador do Varnish, velho conhecido da comunidade FreeBSD. Esse analista trabalhou muitos anos no Kernel do FreeBSD além de ter em seu currículo a participação em projetos de renome como a implementação do algoritmo MD5.
O resultado desta empreitada foi a publicação, em 6 meses, da primeira versão do Varnish. Os testes de benchmark apresentavam um aumento no desempenho de cerca de 600% em relação ao Squid. Segundo depoimento de Anders Berg, da VG Multimédia [7], com a utilização desse novo sistema, eles conseguiram trocar 12 servidores com o Squid para somente 2 com o Varnish. Posteriormente, em 2007, o código da aplicação foi reescrito na versão 2.0, aumentando ainda mais o desempenho e estabilidade deste proxy.
Rapidamente diversos grandes sites têm implementado essa solução em sua arquitetura. Hagelund [8], Mullenweg [9] e Schofmann [10] citam como sites que utilizam o Varnish: o sistema de buscas do Twitter, o Globo.com, Wordpress.com e o CreativeCommons.org.
Este trabalho se divide em duas partes. A primeira parte tem como objetivo introduzir o leitor nas principais características e funcionalidades do Varnish. Na segunda parte consta a realização de testes de Benchmark para averiguar o desempenho desta solução quando utilizada como cache.
2. Parte 1 - Características do Varnish
3. Parte 2 - Testes de benchmark
4. Conclusão
PuTTY - Estabelecendo Chave Secreta com OpenSSH
Configurando uma pasta compartilhada para os usuários do seu Linux
Rodando o macOS com Docker, qemu, e KVM
Diferenças de sites Web Standards
Chrome Remote Desktop - O serviço de acesso remoto do Google
aMSN: MSN messenger turbinado com plugins!
Datagramas IP (Protocolo Internet)
Por que eu pago por 10 megas, mas só faço download a 1 mega?
Passos essenciais para configurar seu modem 3G no Linux
Muito legal.
Gostaria de saber se você já o utilizou na prática, se teria um exemplo de regras.
Participei de alguns testes na época do lançamento do Blog do Planalto em que pudemos por a prova esta ferramenta em uma rede de alta velocidade. Existem varios exemplos de configuração no site do projeto http://varnish-cache.org, mas depende do soft que for utilizar. Por exemplo, utilizei com um sistema de blogs wordpress/buddypress e na epoca eu checava a existência de um cookie para definir se iria fazer cache.
TO curtindo o lance de aprender sobre o varnish.
Pois eu estava lá na palestra na Area 1.
O Varnish tem uma vantagem bem interessante em cima do Squid.
Muito bom, eu estava procurando um artigo desse aqui no VOL há algum tempo atrás, mas não encontrei. Hoje já tenho meu proxy com varnish rodando.
E para controle de internet ? Num ambiente que envolve muitos usuários ?
Gostaria de saber as vatagens do Squid sob o varnish e as desvantagens do varnish. Se alguém puder me dar uma luz, agradeço.
Serviço de hospedagem de sites tam uma fila de atendimento, se o seu servidor consegue atender rapidamente, esta fila se mantem pequena, se ele engasga ela cresce e derruba o serviço. O varnish serve para acelerar o atendimento às requisições mantendo as páginas em memoria.
O squid perde de longe para esta belezinha, ele não consegue gerenciar corretamente a memoria nem distribuir seus jobs pelos núcleos do computador.
Estou usando a versão 2.1 do Varnish baixada do repositório do Ubuntu. Segui algumas configurações sugeridas no site http://varnish-cache.org, porém são para versão 2.0 e estou enfrentando algumas dificuldades devido a interpretação de comandos por esta versão. Não tenho grande experiência nas linguagens C e Perl. Alguém pode me ajudar? Segue o erro retornado:
root@marco-desktop:/home/marco# varnishd -a :80 -T localhost:6082 -f /etc/varnish/teste.vcl -s file,/var/cache/varnish.cache,512M
storage_file: filename: /var/cache/varnish.cache size 512 MB.
Message from VCC-compiler:
Invalid assignment operator ';' only '=' is legal for strings
Message from C-compiler:
./vcl.1P9zoqAU.c: In function VGC_function_vcl_fetch:
./vcl.1P9zoqAU.c:736: error: expected ) before ; token
./vcl.1P9zoqAU.c:738: error: invalid use of void expression
./vcl.1P9zoqAU.c:738: error: expected ; before } token
Running C-compiler failed, exit 1
VCL compilation failed
Valeu!
Fiz a instalação do Varnish 2.1 no Ubuntu Lucid e a instalação padrão esta funcionando blz, tb testei este comando q vc enviou mudando somente o aquivo teste.vcl para default.vcl q é o padrão instalado e também funcionou normal. A falha esta em seu vcl, coloque o conteúdo padrão nele conforme abaixo e teste novamente para ver se funciona. Qualquer coisa meu mail é alexandrehaguiar arroba gmail.com.
backend default {
.host = "127.0.0.1";
.port = "8080";
}
Olá Alexandre
Não funcionou. Enviei um e-mail com meu arquivo vcl, ok!
Obrigado pela ajuda!
tinha lido sobre as vantagens dele sobre o squid... mas será que tem como fazer ele trabalhar como cache web normal (nao reverso) ?
Ele foi feito para trabalhar especificamente como proxy reverso e não tem outros recursos que o squid possui necessários para uma ferramenta de proxy.
Cara... Onde fica e como faço pra limpar o cache do varnish? Sabe me falar?
Eu queria saber se utilizando o varnish com a seguinte configuração eu tenho um acréscimo na segurança.
Eu tenho muitos ataques a sites wordpress, então pensei em isolar os clientes em um servidor X e liberar o acesso para o servidor Y que hospeda o varnish. Assim, apenas o servidor X terá acesso aos servidor Y(meus clientes wordpress).
Como esses ataques acontecem de forma automática e infectam com malware, queria saber se essa configuração isola os PHPs dosmeus sites wordspress.
vlw
O varnish pode ajudar em ataques de negação de serviço mas não em ataques com bots.
Você pode tentar proteger as páginas wp-login e wp-admin com uma autenticação básica adicional para evitar que os scripts funcionem... pode até interligar esta autenticação básica com um sistema de firewall como o csf (http://configserver.com/cp/csf.html) e fazer com que o usuário fique bloqueado apos certo número de erros. Cuidado no entanto para não bloquear seus clientes;)
O melhor mesmo seria bloquear estes links para acesso somente por uma rede especifica...
Patrocínio

Destaques
Artigos
Criptografando sua Home com Gocryptfs para tristeza do meliante
A Involução do Linux e as Lambanças Desnecessárias desde o seu Lançamento
O Journal no Linux para a guarda e consulta de logs do sistema
A evolução do Linux e as mudanças que se fazem necessárias desde o seu lançamento
Dicas
Discos que não instalam o sistema por erro MBR/GPT no Linux
Hospedagem de Mangás com Kavita e Docker para Acesso Remoto via Tailscale
Aplicar tema e ícones do Ubuntu Cinnamon no Arch Linux sem AUR
Tópicos
Enquete: qual bloco de código C++ é mais legível? (3)
Instalação do driver Epson L3150 [RESOLVIDO] (5)
Top 10 do mês
-

Xerxes
1° lugar - 151.054 pts -

Fábio Berbert de Paula
2° lugar - 77.821 pts -

Buckminster
3° lugar - 47.210 pts -

Alberto Federman Neto.
4° lugar - 44.030 pts -

Alessandro de Oliveira Faria (A.K.A. CABELO)
5° lugar - 34.085 pts -

edps
6° lugar - 31.697 pts -

Sidnei Serra
7° lugar - 25.477 pts -

Mauricio Ferrari (LinuxProativo)
8° lugar - 24.879 pts -

Daniel Lara Souza
9° lugar - 23.623 pts -

Andre (pinduvoz)
10° lugar - 22.186 pts
Scripts
A maior comunidade GNU/Linux da América Latina! Artigos, dicas, tutoriais, fórum, scripts e muito mais. Ideal para quem busca auto-ajuda.
Site hospedado por: