Migração de arquivos do tipo BLOB para sistema de arquivos
Em determinada fase de um projeto, pode ser necessário realizar a migração de arquivos do tipo BLOB armazenados em um banco de dados, para sistema de arquivos. Há diversas formas de realizar esse procedimento. Neste artigo irei demonstrar como realizar essa migração de dados, fazendo a leitura de arquivos em formato PDF a partir do SGBD Oracle e, gravando em disco, utilizando a linguagem de programação Python.
[ Hits: 10.102 ]
Por: Anderson Ribeiro em 09/05/2018

Requisitos da migração
1°) Os arquivos deverão ser gravados em disco, de acordo com o campo da data de inclusão (DTHINCLUSAO), ou seja, deverá ser criada uma hierarquia de diretórios ano/mes/dia. Portanto, se um registro possui uma data 30/05/2016, o arquivo deverá ser gravado em um diretório 2016/05/30.
2°) Ao gravar em disco, duas colunas precisarão ser atualizadas: DS_PATH_ARQUIVO com o path e DS_ARQUIVO com o nome do arquivo o qual foi gravado no sistema de arquivos.
3°) Em relação ao nome do arquivo, observe um cenário em que uma empresa possua centenas de milhares de arquivos em banco, devemos evitar a colisão de nomes em disco, então para contornar essa situação, iremos utilizar o módulo uuid, identificador universalmente exclusivo, para gerar os nomes dos arquivos criando strings únicas que garantam unicidade.
Código da migração
Para saber como configurar uma instância cliente do Oracle, e como configurar o Python para conectar ao banco de dados, há um artigo publicado anteriormente, explicando o passo a passo: Configurando uma instância do Oracle para acesso via Python [Artigo]Vamos iniciar o código realizando os imports dos módulos.

Agora vamos criar três funções: uma para conectar ao banco de dados, outra para escrever o arquivo em disco e a terceira função para criar o diretório.
Função para conectar ao Oracle:

A nossa próxima função será para gravar o arquivo "pdf" em disco:

Na linha 12, veja que é utilizado o modo "wb", o qual significa escrita de binários. Na linha 13, a função "write" é a responsável por gravar o arquivo em disco.
A função a seguir cria o diretório em disco:
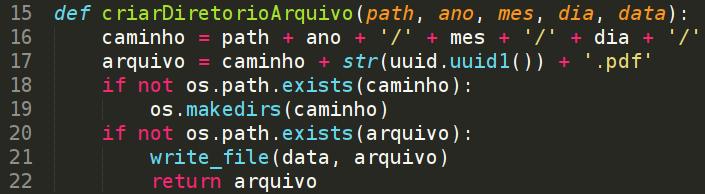
Veja que a função "criarDiretorioArquivo" recebe cinco parâmetros: path (caminho do sistema de arquivos), ano, mês, dia e data (arquivo pdf).
Observe as linhas 16 e 17, a variável "caminho" realiza a concatenação de todo o path e a variável "arquivo" concatena o path acrescido do nome do arquivo com a extensão ".pdf". Em um dos requisitos, foi mencionado que deveríamos evitar a colisão de nomes, então para isso foi utilizado str(uuid.uuid1()). Está sendo criada uma cadeia de 32 dígitos hexadecimais e a função "str" faz a conversão para string. Na linha 18 é verificado se o diretório não existe, caso não exista ele será criado, caso exista, o código partirá para a verificação na linha 20, como o arquivo não existe ele será criado com a chamada da função "write_data" na linha 21.
Com a criação dessas três funções, nosso código "main" ficará bem enxuto. Agora vamos para a função principal:
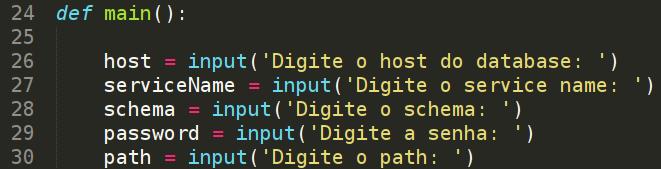
Vamos ao próximo trecho do código:

Agora vamos para a última parte do código:
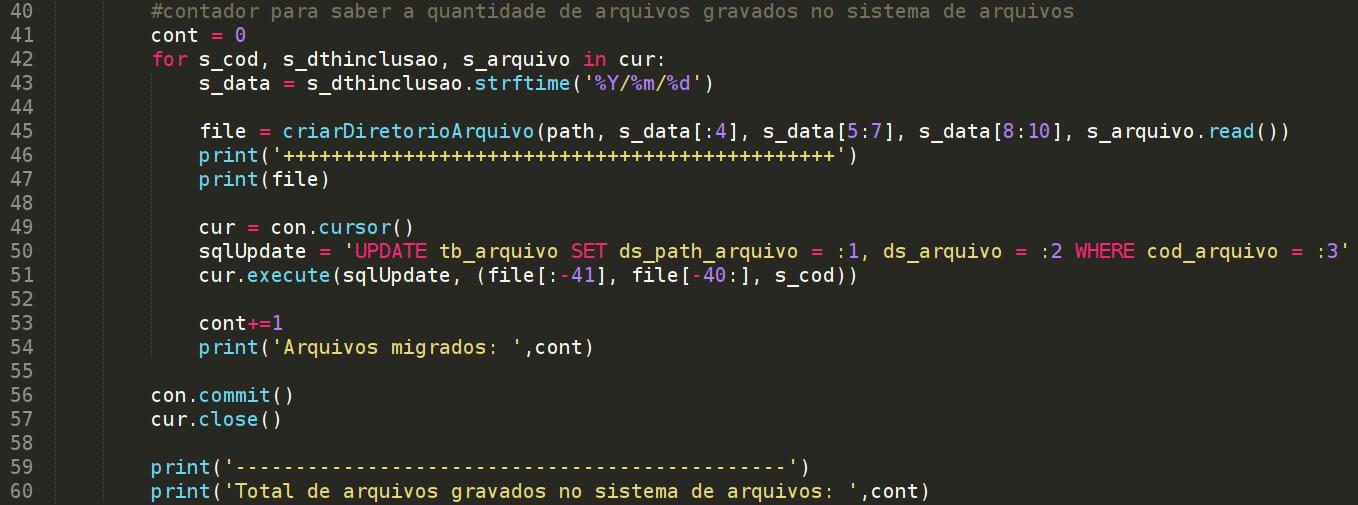
Na linha 45 chamamos a função "criarDiretorioArquivo", que além de criar os diretórios, também vai gravar o arquivo. No primeiro parâmetro passamos o path do sistema de arquivos, nos segundo, terceiro e quarto parâmetros, é utilizado o operador de slice, para obter o ano, mês e dia, pois a data está sendo obtida assim: 2016/05/30. Portanto, o path é concatenado com essa nova estrutura de diretórios. E no último parâmetro, "s_arquivo.read()" obtemos o arquivo BLOB para gravar em disco.
Na linha 49 abrimos um novo cursor para executar a instrução SQL na linha seguinte, para atualizar as colunas ds_path_arquivo e ds_arquivo para cada registro.
Agora, muita atenção quanto à linha 51. O nome do arquivo gerado fica nesse formato b75b6632-33a5-11e8-8b38-847bebfeb61e concatenado com a extensão do arquivo que é ".pdf", a string fica assim: b75b6632-33a5-11e8-8b38-847bebfeb61e.pdf. Essa string possui 40 caracteres, então para obter todo o path para atualizar a coluna "ds_path_arquivo", basta utilizar o slice file[:-41], assim vamos extrair tudo que estiver antes dos 40 caracteres do nome do arquivo. E para atualizar a coluna ds_arquivo com o nome do arquivo, extraímos os últimos 40 caracteres, utilizando file[-40:]. O terceiro parâmetro "s_cod" é para diferenciar cada registro que está sendo atualizado.
Estou considerando o cenário do tudo ou nada, pois o commit só é feito no final.
No link a seguir é possível baixar o código de migração: https://pastebin.com/UDQEjhuv
Por fim, basta executar pelo terminal, lembrando que é necessário executá-lo na máquina do sistema de arquivos:
python MigracaoDados.py
Na imagem a seguir veja o resultado da execução:

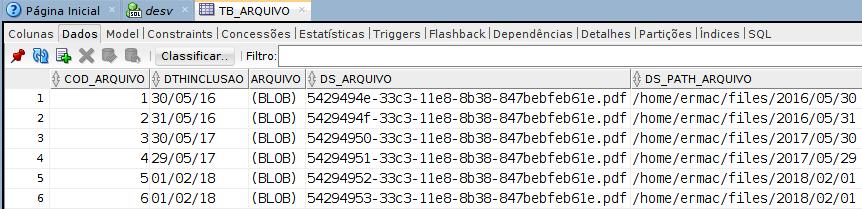
E na próxima imagem, os arquivos gravados em disco:

Caso vá reutilizar esse código de acordo com algum cenário da sua empresa, é interessante renomear a coluna "arquivo" e verificar se a aplicação passará a enxergar esses arquivos em disco. Portanto, após ter certeza de que a migração foi realizada com sucesso e a aplicação não acessa mais a coluna com os arquivos binários, a coluna poderá ser excluída da tabela.
A critério de informação, esse código foi utilizado em um cenário real na empresa a qual trabalho, onde tivemos que migrar pouco mais de 320 mil arquivos do banco para sistema de arquivos. O desempenho da migração vai depender do poder de processamento da máquina. Numa máquina do ambiente de testes, com um hardware não tão robusto, todos esses arquivos foram migrados em torno de 3h:30, enquanto que em outra máquina com as configurações similares ao ambiente de produção, todos os arquivos foram migrados em aproximadamente 2h.
Conclusão
Espero que o artigo tenha sido relevante para o aprendizado e possa servir como base para atender alguma necessidade que a sua empresa tenha, basta realizar as devidas adaptações no código, seguindo os requisitos de negócio estipulados.Qualquer sugestão, crítica ou dúvida, sinta-se a vontade e deixe nos comentários.
Até a próxima!
2. Requisitos da migração
Configurando uma instância do Oracle para acesso via Python
Oracle 10g: Startup automático
Instalação database Oracle 11G x86 e 64 no Ubuntu 10.10 Server
Principais Processos em Background do Banco de Dados Oracle
Instalação do Oracle 9i no Red Hat AS 4
Nenhum comentário foi encontrado.
Patrocínio

Destaques
Artigos
Instalação e Configuração do Void com Cinnamon
Porque Gentoo semi-binário atualmente (desabafo)
A combinação de WMs com compositores feitos por fora
Audacious, VLC e QMMP - que saudades do XMMS
SUNO OpenSource: Crie um servidor de gerador de música com IA
Dicas
Aparecer o Chuck Norris no seu terminal
[Resolvido] Jogo Portal fechando
Como configurar cores no prompt do Bash para usuário e root no Arch Linux
Tópicos
Top 10 do mês
-

Xerxes
1° lugar - 135.222 pts -

Fábio Berbert de Paula
2° lugar - 65.672 pts -

Buckminster
3° lugar - 43.722 pts -

Alberto Federman Neto.
4° lugar - 31.291 pts -

Alessandro de Oliveira Faria (A.K.A. CABELO)
5° lugar - 22.043 pts -

Daniel Lara Souza
6° lugar - 21.232 pts -

edps
7° lugar - 21.089 pts -

Mauricio Ferrari (LinuxProativo)
8° lugar - 20.357 pts -

Sidnei Serra
9° lugar - 17.857 pts -

Andre (pinduvoz)
10° lugar - 15.415 pts
Scripts
A maior comunidade GNU/Linux da América Latina! Artigos, dicas, tutoriais, fórum, scripts e muito mais. Ideal para quem busca auto-ajuda.
Site hospedado por: