Falha add cluster Proxmox (2 nós)
1. Falha add cluster Proxmox (2 nós)

mproenca
(usa Debian)
Enviado em 29/08/2025 - 09:14h
Já aconteceu isto com vocês?Olá a todos.
Eu tenho feito muitas instalações de Proxmox, standalone e cluster. 90% sem erros ou falhas em servidores Dell/HP
Normalmente uso em minha infra.
2 nós proxmox
1 servidor Truenas para armazenar os discos das VMs.
1 PBS (virtual ou fisico dependendo do projeto)
Caso.
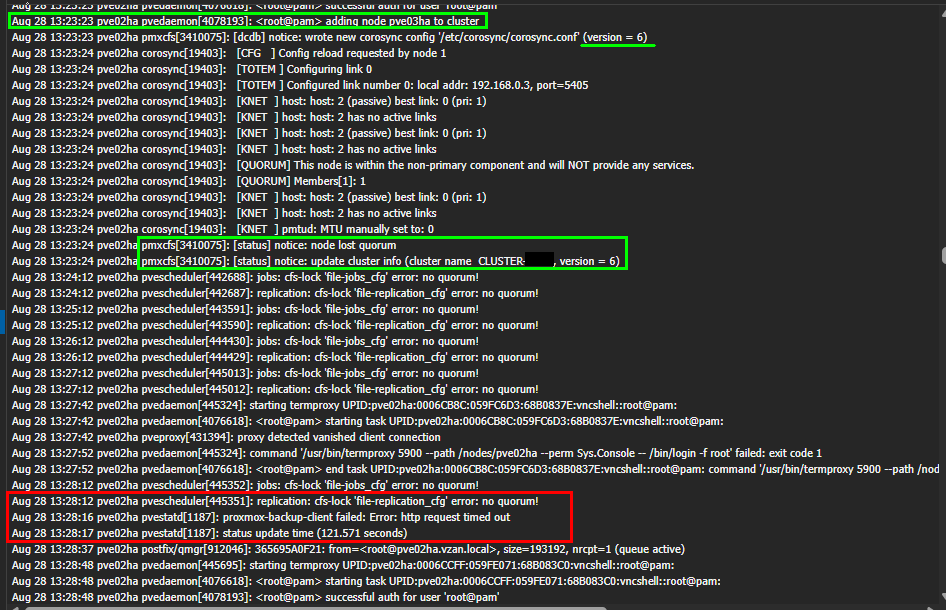
Estou criando um cluster em um cliente, remotamente, usando iDrac.
Ao adicionar o servidor ao Cluster, ele da falha, e então preciso fazer o rollback.
Sempre seguindo documentação
https://pve.proxmox.com/wiki/Cluster_Manager
Em nosso LAB todos os testes foram feitos, mas tem 1 que ainda não fiz.
Colocar um switch swap no local para montar o Cluster, eu acredito que a falha esta ocorrendo devido
as configurações do switch do cliente, o qual não tenho autonomia nem acesso para verificar as politicas e configurações.
Neste cenarios, temos
1 S4 (pfsense) virtualizado que recebe os 2 links Wan (Em ambos servidores proxmox tem 4 interfaces de rede. 1-LAN -2 WAN - 3 Wan2 4-Hotspot)
Aug 27 12:09:52 pve02ha pvedaemon[3490909]: <root@pam> adding node pve03ha to cluster
Aug 27 12:09:52 pve02ha pmxcfs[3410075]: [dcdb] notice: wrote new corosync config '/etc/corosync/corosync.conf' (version = 4)
Aug 27 12:09:53 pve02ha corosync[3474422]: [CFG ] Config reload requested by node 1
Aug 27 12:09:53 pve02ha corosync[3474422]: [TOTEM ] Configuring link 0
Aug 27 12:09:53 pve02ha corosync[3474422]: [TOTEM ] Configured link number 0: local addr: 192.168.0.3, port=5405
Aug 27 12:09:53 pve02ha corosync[3474422]: [QUORUM] This node is within the non-primary component and will NOT provide any services.
Aug 27 12:09:53 pve02ha corosync[3474422]: [QUORUM] Members[1]: 1
Aug 27 12:09:53 pve02ha corosync[3474422]: [KNET ] host: host: 2 (passive) best link: 0 (pri: 0)
Aug 27 12:09:53 pve02ha corosync[3474422]: [KNET ] host: host: 2 has no active links
Aug 27 12:09:53 pve02ha corosync[3474422]: [KNET ] host: host: 2 (passive) best link: 0 (pri: 1)
Aug 27 12:09:53 pve02ha corosync[3474422]: [KNET ] host: host: 2 has no active links
Aug 27 12:09:53 pve02ha corosync[3474422]: [KNET ] host: host: 2 (passive) best link: 0 (pri: 1)
Aug 27 12:09:53 pve02ha corosync[3474422]: [KNET ] host: host: 2 has no active links
Aug 27 12:09:53 pve02ha corosync[3474422]: [KNET ] pmtud: MTU manually set to: 0
Aug 27 12:09:53 pve02ha pmxcfs[3410075]: [status] notice: node lost quorum
Aug 27 12:09:53 pve02ha pmxcfs[3410075]: [status] notice: update cluster info (cluster name CLUSTER-MAIN, version = 4)
Aug 27 12:10:10 pve02ha pvescheduler[4014189]: replication: cfs-lock 'file-replication_cfg' error: no quorum!
Aug 27 12:10:10 pve02ha pvescheduler[4014190]: jobs: cfs-lock 'file-jobs_cfg' error: no quorum!
Aug 27 12:10:15 pve02ha postfix/smtp[4013604]: connect to mail-com-br.mail.protection.outlook.com[52.xxx.xxx.13]:25: Connection timed out
Aug 27 12:10:26 pve02ha pvedaemon[3498708]: <root@pam> successful auth for user 'user@pve'
Aug 27 12:10:45 pve02ha postfix/smtp[4013604]: connect to ti-com-br.mail.protection.outlook.com[2a01:xxx:xxx:f913::1]:25: Connection timed out
Aug 27 12:11:10 pve02ha pvescheduler[4014580]: jobs: cfs-lock 'file-jobs_cfg' error: no quorum!
Aug 27 12:11:10 pve02ha pvescheduler[4014579]: replication: cfs-lock 'file-replication_cfg' error: no quorum!
Aug 27 12:11:15 pve02ha postfix/smtp[4013604]: connect to ti-com-br.mail.protection.outlook.com[2a01:xxx:xxx:f805::]:25: Connection timed out
Aug 27 12:11:15 pve02ha postfix/smtp[4013604]: 9B36B5A0F3F: to=<suporte@ti.com.br>, relay=none, delay=222848, delays=222682/0.02/166/0, dsn=4.4.1, status=deferred (connect to ti-com-br.mail.protection.outlook.com[2a01:xxx:xxx:f805::]:25: Connection timed out)
Aug 27 12:11:27 pve02ha pvedaemon[3495868]: <root@pam> successful auth for user 'root@pam'
Aug 27 12:12:10 pve02ha pvescheduler[4014971]: jobs: cfs-lock 'file-jobs_cfg' error: no quorum!
Aug 27 12:12:10 pve02ha pvescheduler[4014970]: replication: cfs-lock 'file-replication_cfg' error: no quorum!
Aug 27 12:12:16 pve02ha pvedaemon[3490909]: <root@pam> successful auth for user 'root@pam'
Aug 27 12:13:10 pve02ha pvescheduler[4015133]: jobs: cfs-lock 'file-jobs_cfg' error: no quorum!
Aug 27 12:13:10 pve02ha pvescheduler[4015132]: replication: cfs-lock 'file-replication_cfg' error: no quorum!
Aug 27 12:13:29 pve02ha postfix/qmgr[912046]: 63D945A0F63: from=<root@pve02ha.local>, size=192682, nrcpt=1 (queue active)
Aug 27 12:14:10 pve02ha pvescheduler[4015185]: jobs: cfs-lock 'file-jobs_cfg' error: no quorum!
Aug 27 12:14:10 pve02ha pvescheduler[4015184]: replication: cfs-lock 'file-replication_cfg' error: no quorum!
Aug 27 12:14:13 pve02ha pvestatd[1187]: status update time (121.059 seconds)
Aug 27 12:15:10 pve02ha pvescheduler[4015569]: jobs: cfs-lock 'file-jobs_cfg' error: no quorum!
Aug 27 12:15:10 pve02ha pvescheduler[4015568]: replication: cfs-lock 'file-replication_cfg' error: no quorum!
Aug 27 12:15:15 pve02ha postfix/smtp[4015158]: connect to ti-com-br.mail.protection.outlook.com[2a01:xxx:xxx:c92c::]:25: Connection timed out
Aug 27 12:15:45 pve02ha postfix/smtp[4015158]: connect to ti-com-br.mail.protection.outlook.com[2a01:xxx:xxx:c902::7]:25: Connection timed out
Aug 27 12:16:10 pve02ha pvescheduler[4015965]: jobs: cfs-lock 'file-jobs_cfg' error: no quorum!
Aug 27 12:16:10 pve02ha pvescheduler[4015964]: replication: cfs-lock 'file-replication_cfg' error: no quorum!
Aug 27 12:16:15 pve02ha postfix/smtp[4015158]: connect to ti-com-br.mail.protection.outlook.com[52.xxx.xxx.6]:25: Connection timed out
Aug 27 12:16:15 pve02ha postfix/smtp[4015158]: 63D945A0F63: to=<suporte@ti.com.br>, relay=none, delay=130478, delays=130312/0.02/166/0, dsn=4.4.1, status=deferred (connect to ti-com-br.mail.protection.outlook.com[52.xxx.xxx.6]:25: Connection timed out)
Aug 27 12:17:01 pve02ha CRON[4016358]: pam_unix(cron:session): session opened for user root(uid=0) by (uid=0)
Aug 27 12:17:01 pve02ha CRON[4016359]: (root) CMD (cd / && run-parts --report /etc/cron.hourly)
Aug 27 12:17:01 pve02ha CRON[4016358]: pam_unix(cron:session): session closed for user root
Aug 27 12:17:10 pve02ha pvescheduler[4016357]: jobs: cfs-lock 'file-jobs_cfg' error: no quorum!
Aug 27 12:17:10 pve02ha pvescheduler[4016356]: replication: cfs-lock 'file-replication_cfg' error: no quorum!
Aug 27 12:18:10 pve02ha pvescheduler[4016747]: jobs: cfs-lock 'file-jobs_cfg' error: no quorum!
Aug 27 12:18:10 pve02ha pvescheduler[4016746]: replication: cfs-lock 'file-replication_cfg' error: no quorum!
Aug 27 12:18:48 pve02ha pveproxy[1226]: worker 4001912 finished
Aug 27 12:18:48 pve02ha pveproxy[1226]: starting 1 worker(s)
Aug 27 12:18:48 pve02ha pveproxy[1226]: worker 4017072 started
Aug 27 12:18:49 pve02ha pveproxy[4017071]: worker exit
Aug 27 12:19:10 pve02ha pvescheduler[4017137]: jobs: cfs-lock 'file-jobs_cfg' error: no quorum!
Aug 27 12:19:10 pve02ha pvescheduler[4017136]: replication: cfs-lock 'file-replication_cfg' error: no quorum!
Aug 27 12:19:25 pve02ha pmxcfs[3410075]: [dcdb] notice: data verification successful
Aug 27 12:19:53 pve02ha pveproxy[4007688]: worker exit
Aug 27 12:19:53 pve02ha pveproxy[1226]: worker 4007688 finished
Aug 27 12:19:53 pve02ha pveproxy[1226]: starting 1 worker(s)
Aug 27 12:19:53 pve02ha pveproxy[1226]: worker 4017470 started
Aug 27 12:20:10 pve02ha pvescheduler[4017534]: jobs: cfs-lock 'file-jobs_cfg' error: no quorum!
Aug 27 12:20:10 pve02ha pvescheduler[4017533]: replication: cfs-lock 'file-replication_cfg' error: no quorum!
Aug 27 12:21:10 pve02ha pvescheduler[4017955]: jobs: cfs-lock 'file-jobs_cfg' error: no quorum!
Aug 27 12:21:10 pve02ha pvescheduler[4017954]: replication: cfs-lock 'file-replication_cfg' error: no quorum!
Aug 27 12:22:10 pve02ha pvescheduler[4018436]: jobs: cfs-lock 'file-jobs_cfg' error: no quorum!
Aug 27 12:22:10 pve02ha pvescheduler[4018435]: replication: cfs-lock 'file-replication_cfg' error: no quorum!
Aug 27 12:23:10 pve02ha pvescheduler[4018709]: jobs: cfs-lock 'file-jobs_cfg' error: no quorum!
Aug 27 12:23:10 pve02ha pvescheduler[4018708]: replication: cfs-lock 'file-replication_cfg' error: no quorum!
Aug 27 12:24:10 pve02ha pvescheduler[4018759]: jobs: cfs-lock 'file-jobs_cfg' error: no quorum!
Aug 27 12:24:10 pve02ha pvescheduler[4018758]: replication: cfs-lock 'file-replication_cfg' error: no quorum!
Aug 27 12:24:23 pve02ha pvestatd[1187]: proxmox-backup-client failed: Error: http request timed out
Aug 27 12:24:24 pve02ha pvestatd[1187]: status update time (120.996 seconds)
Aug 27 12:25:10 pve02ha pvescheduler[4019070]: jobs: cfs-lock 'file-jobs_cfg' error: no quorum!
Aug 27 12:25:10 pve02ha pvescheduler[4019069]: replication: cfs-lock 'file-replication_cfg' error: no quorum!
Aug 27 12:25:26 pve02ha pvedaemon[3490909]: <root@pam> successful auth for user 'user@pve'
Aug 27 12:26:10 pve02ha pvescheduler[4019460]: jobs: cfs-lock 'file-jobs_cfg' error: no quorum!
Aug 27 12:26:10 pve02ha pvescheduler[4019459]: replication: cfs-lock 'file-replication_cfg' error: no quorum!
Aug 27 12:27:10 pve02ha pvescheduler[4019853]: jobs: cfs-lock 'file-jobs_cfg' error: no quorum!
Aug 27 12:27:10 pve02ha pvescheduler[4019852]: replication: cfs-lock 'file-replication_cfg' error: no quorum!
Aug 27 12:27:16 pve02ha pvedaemon[3495868]: <root@pam> successful auth for user 'root@pam'
Aug 27 12:27:24 pve02ha pveproxy[1226]: worker 4008740 finished
Patrocínio

Destaques
Artigos
Migração de Arch Linux para repositórios CachyOS (Uso de Instruções v3 e v4)
Boas Práticas e Padrões Idiomáticos em Go e C
Vale a pena ter mais de uma interface grafica no seu Linux?
Dicas
[Resolvido] Google Chrome reclamando de perfil em uso após mudar hostname
Instalando o Tema de Ícones Tela Circle
Copiar Para e Mover Para no menu de contexto do Nautilus e Dolphin
Dotando o Thunar das opcoes Copiar para e Mover para no menu de contexto
Tópicos
Instalação Dual Boot Linux+Windows 11 (4)
No Ubuntu 26.04, sudo passou a mostrar os asteriscos ao digitar por pa... (5)
Como instalar Warsaw no Gentoo? (0)
Como insiro e excluo um elemento XML e JSON ao código Javascript (1)
Top 10 do mês
-

Xerxes
1° lugar - 130.777 pts -

Fábio Berbert de Paula
2° lugar - 66.181 pts -

Buckminster
3° lugar - 39.952 pts -

Alberto Federman Neto.
4° lugar - 34.261 pts -

Alessandro de Oliveira Faria (A.K.A. CABELO)
5° lugar - 23.411 pts -

edps
6° lugar - 22.184 pts -

Daniel Lara Souza
7° lugar - 21.095 pts -

Mauricio Ferrari (LinuxProativo)
8° lugar - 19.972 pts -

Sidnei Serra
9° lugar - 19.825 pts -

Andre (pinduvoz)
10° lugar - 16.134 pts
Scripts
A maior comunidade GNU/Linux da América Latina! Artigos, dicas, tutoriais, fórum, scripts e muito mais. Ideal para quem busca auto-ajuda.
Site hospedado por: