Instalando Apache Hadoop
Esse artigo tende a tentar explicar a instalação e configuração do Apache Hadoop 2 em suas três maneiras de instalação.
[ Hits: 31.472 ]
Por: Eduardo Ferreira Mendes em 14/08/2015 | Blog: https://github.com/z4r4tu5tr4

O que é o Apache Hadoop
Estrutura Hadoop
Segundo Carmen Placios a arquitetura das versões do Hadoop 0 e 1 se dividem em três pilares fundamentais:- Hadoop MapReduce: que podemos definir como o motor ou modelo de programação que impulsiona o Hadoop.
- Sistema de arquivos: Hadoop utiliza seu próprio sistema de arquivos distribuídos, denominado Apache Hadoop Distributed File System (HDFS).
- Hadoop Common: utilitários que possibilitam a integração dos subprojetos do ecossistema Hadoop.
Durante o processo de amadurecimento do Apache Hadoop um quarto pilar, denominado Yarn, foi inserido a partir da versão 2 (Apache, 2012):
Hadoop Yarn: pode ser considerado a evolução do MapReduce, ou MRv2 como veremos mais adiante.
MapReduce
Uma aplicação MapReduce em execução no Hadoop recebe seu trabalho dividido entre os nós - computadores que formam um cluster geralmente são chamados de nós - e os arquivos a serem manipulados pela aplicação residem no sistema de arquivos, HDFS, o que mantém a entrada e saída a um baixo custo (deRoss; et al, 2014).Em linhas gerais, o Hadoop fragmenta os dados no seu sistema de arquivos quando a função map é utilizada e destes fragmentos são geradas tuplas formadas por (chave, valor) produzindo um novo conjunto de chaves e valores intermediários e aplica a função shuffle para classificar todos os valores iguais a uma mesma chave para reduzir as tarefas. Em sequência os nós executam a função de redução e processam as tuplas geradas pela função shuffle produzindo uma tupla única para cada valor e chave correspondentes. A função de redução também se encarrega de escrever as saídas de dados no sistema de arquivos distribuído. Para exemplificar todo esse processo, vamos observar a imagem 1:
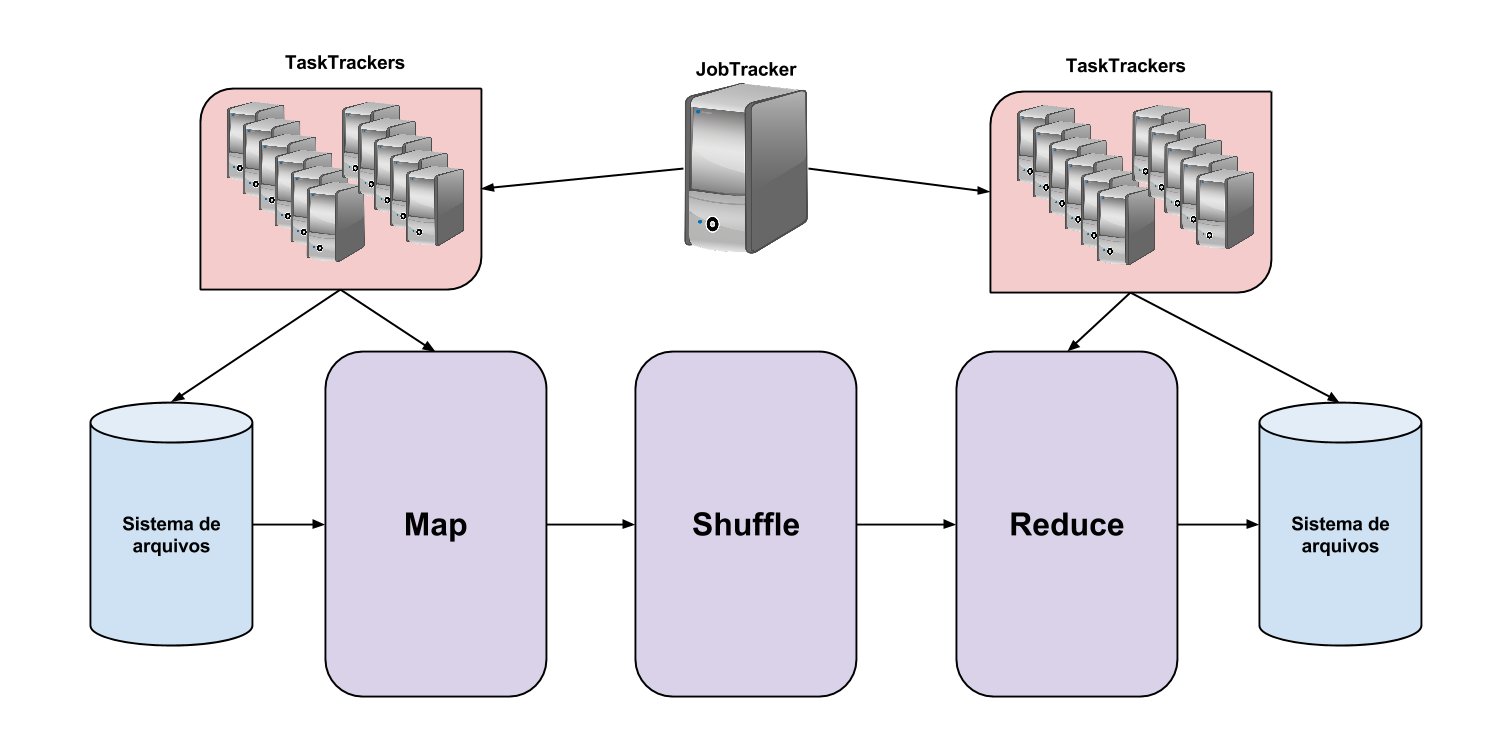
Fonte: Adaptado de Apache, 2014
HDFS
Como vimos o MapReduce segue sua hierarquia de nós e com o HDFS não é diferente. Existe o NameNode, ou master, que é responsável pelo controle de acesso, organização dos diretórios e metadados. Os DataNodes, ou workers, que são responsáveis pelos fragmentos de arquivos e suas replicações, como podemos ver na imagem 2: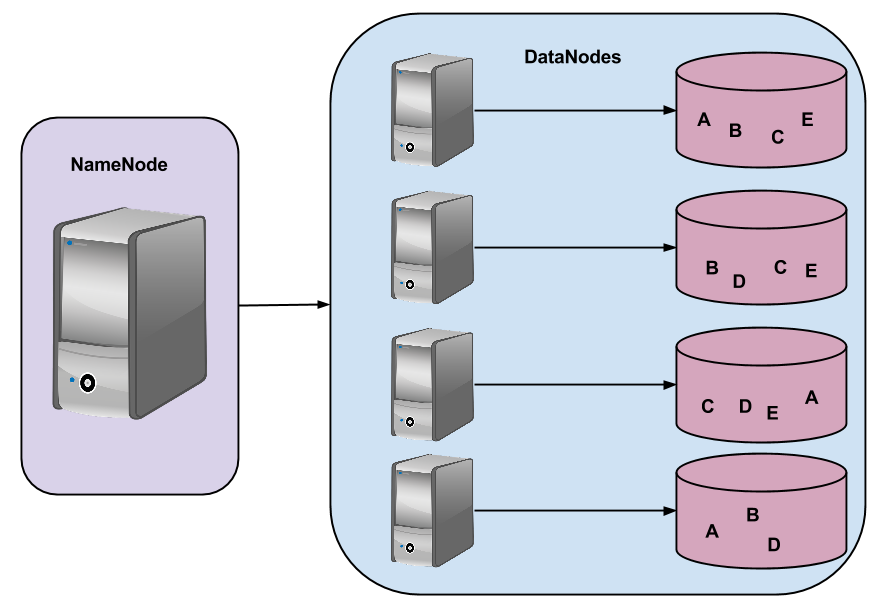
Fonte: Adaptada de Apache 2014
Yarn
Como dito anteriormente, o Yarn é uma evolução do MapReduce onde as funções do JobTracker são repartidas em deamons independentes. Uma das funções principais do MapReduce é a de partilhar os dados para as funções de Map e Reduce, a outra função é gerenciar as falhas e procurar nós disponíveis para executar a função onde houve falha. Para isso o Yarn muda um pouco a nomenclatura do nó master e o apelida de Resource Manager (RM) ou Application Master (AM), onde cada função MapReduce é uma aplicação definida pelo nó mestre e o resource manager fica responsável por reordenar os nós no caso de falhas dos nós escravos, NodeManager (NM). (Apache, 2014)Hadoop commom
Por trás do Hadoop não existem só o MapReduce e HDFS, existe um ecossistema com mais de uma dezena de projetos relacionados e que podem facilitar atividades e a configuração de um cluster. Em grande parte projetos do ecossistema também são hospedados pela Apache Software Foundation (deRoss; et al, 2014) e agora veremos alguns dos principais projetos (Apache, 2014):- Ambari: um framework web para construção, monitoramento e manutenção de um cluster Hadoop, fornecendo uma interface amigável para tais funções e uma sessão para inclusão ou exclusão de nós escravos. Disponível em: http://ambari.apache.org
- Avro: um sistema para serialização de dados, compactando-os em formato binário. Disponível em: http://avro.apache.org
- Cassandra: um banco de dados que preza por escalabilidade, alta disponibilidade e tolerância a falhas para hardware commodity. Disponível em: http://cassandra.apache.org
- Chukwa: um framework escalável para análises de logs. Disponível em: http://chukwa.apache.org
- Hbase: um banco de dados escalável, distribuído, que suporta o armazenamento de dados estruturado para grandes mesas. Disponível em: http://hbase.apache.org
- Hive: uma infraestrutura para Datawarehouse que tem como característica um compactador próprio e um sistema para consultas ad hoc. Disponível em: http://hive.apache.org
- Mahout: um framework escalável para machine learning e data mining. Disponível em: http://mahout.apache.org
- Pig: uma plataforma para análise de grandes conjuntos de dados que roda sobre o HDFS, como um compilador próprio para produzir programas de MapReduce usando uma linguagem de programação chamada Pig Latin. Disponível em: http://pig.apache.org
- Sqoop: uma ferramenta para mover dados de bases relacionais para o HDFS.
- ZooKeeper: um framework coordenador de computação distribuída altamente confiável, como nomes, configuração e sincronização entre os nós. Disponível em: http://zookeeper.apache.org

Características do Hadoop
Como dito anteriormente o Hadoop é um sistema tolerante a falhas, com grande confiabilidade e alta escalabilidade e para exemplificar podemos usar como exemplo um programa que roda em um único computador. Quando o programa falha, ele simplesmente finaliza, mas em um sistema distribuído a noção de falha se faz parcial, pois somente um único nó pode falhar, ou um conjunto deles. Sobre a grande confiabilidade pode-se afirmar que um cluster deve funcionar durante um grande período de tempo sem interrupções (Tanenbaum & Steen, 2010).A alta escalabilidade do Hadoop é referente a facilidade de administração quanto a inserção de novos nós para crescimento (Shvachko, 2010). O que pode aumentar seu poder de processamento de forma simples e barata, pois o Hadoop usa hardware commodity (White, 2014).
2. Instalação do modo Single-Node
3. Instalação do modo Pseudo-Distribuído
4. Instalação do modo totalmente distribuído
5. Referências
Como colocar um programa para inicializar no boot
HOWTO - Usando PSP no Gentoo Linux
Instalando e configurando o PostgreSQL
Samba + LDAP + Squid no Debian
Ótimo trabalho, será de grande uso. Mt Obrigado.
Poderia informar os requisitos necessários?
[1] Comentário enviado por HenriqueSantana em 28/04/2016 - 15:47h
Ótimo trabalho, será de grande uso. Mt Obrigado.
Poderia informar os requisitos necessários?
Cara, se quiser, me manda um e-mail a gente vai conversando mendesxeduardo at gmail
parabéns, conteúdo muito bom, eu instalei o modo single node, mas fiquei com algumas dúvidas. To querendo usar o hadoop no meu Tcc, mas tô iniciando agora. gostaria de ver as possibilidades.
Patrocínio

Destaques
Artigos
O Journal no Linux para a guarda e consulta de logs do sistema
A evolução do Linux e as mudanças que se fazem necessárias desde o seu lançamento
Maquina modesta - a vez dos navegadores ferrarem o usuario
Fscrypt: protegendo arquivos do seu usuário sem a lentidão padrão de criptograr o disco
Dicas
Sway no Arch Linux: configuração Inicial sem enrolação
Resolvendo o bloqueio do Módulo Warsaw no Arch Linux (Porta 30900)
Tópicos
Continuando meus tópicos anteriores (0)
Saída de loop após teste de if. (2)
Governo da França vai trocar Windows por Linux (9)
Warsaw não é reconhecido no Google Chrome 147.0.7727.55 [RESOLVIDO] (9)
Top 10 do mês
-

Xerxes
1° lugar - 143.511 pts -

Fábio Berbert de Paula
2° lugar - 75.693 pts -

Buckminster
3° lugar - 46.322 pts -

Alberto Federman Neto.
4° lugar - 43.698 pts -

Alessandro de Oliveira Faria (A.K.A. CABELO)
5° lugar - 32.340 pts -

edps
6° lugar - 30.048 pts -

Sidnei Serra
7° lugar - 26.733 pts -

Mauricio Ferrari (LinuxProativo)
8° lugar - 23.557 pts -

Daniel Lara Souza
9° lugar - 22.421 pts -

Andre (pinduvoz)
10° lugar - 20.664 pts
Scripts
A maior comunidade GNU/Linux da América Latina! Artigos, dicas, tutoriais, fórum, scripts e muito mais. Ideal para quem busca auto-ajuda.
Site hospedado por: