Container Elastic Stack para visualização de logs do Proxy Squid
Compartilho neste artigo a minha primeira experiência com o projeto Open Source Elastic Stack, um conjunto de ferramentas para coleta, tratamento e exibição de logs. Demonstrarei como utilizei o Elastic Stack para coletar, tratar e apresentar os logs de acesso do Squid.
[ Hits: 15.079 ]
Por: Thiago Murilo Diniz em 28/07/2017 | Blog: https://br.linkedin.com/in/thiagomdiniz

Introdução
Compartilho neste artigo, a minha primeira experiência com o projeto Open Source Elastic Stack, um conjunto de ferramentas para coleta, tratamento e exibição de logs. Demonstrarei como utilizei o Elastic Stack para coletar, tratar e apresentar os logs de acesso do Squid.
Breve descrição retirada do site da Elastic:
Open Source Elastic Stack: Obtenha dados confiáveis e seguros de qualquer fonte, em qualquer formato e procure, analise e visualize em tempo real.
Ferramentas
O Elastic Stack é formado pelas seguintes ferramentas:Beats → são agentes que você instala em seus servidores para enviar diferentes tipos de dados ao Elasticsearch. Os Beats podem enviar dados diretamente ao Elasticsearch ou enviá-los ao Elasticsearch via Logstash, o qual pode ser utilizado para analisar e transformar os dados.
Dentre os Beats disponívels, utilizaremos o Filebeat, que é um coletor de dados de log para arquivos locais. Instalado como um agente nos servidores, o Filebeat monitora os diretórios de log ou arquivos de log específicos e encaminha o conteúdo ao Elasticsearch (diretamente ou via Logstash) para indexação, atuando como um centralizador de logs. Neste artigo, o Filebeat será responsável por monitorar e encaminhar ao Logstash o conteúdo do arquivo de log de acesso do Squid.
Logstash → é um mecanismo de coleta de dados com capacidades de pipeline de tempo real. O Logstash pode unir dinamicamente dados de fontes diferentes e normalizar os dados em destinos de sua escolha. Neste artigo, o Logstash receberá e normalizará os logs do Squid, os enviando posteriormente ao Elasticsearch.
Elasticsearch → é um mecanismo de pesquisa e análise distribuído baseado em JSON, projetado para escalabilidade horizontal, máxima confiabilidade e gerenciamento fácil. Permite armazenar, pesquisar e analisar rapidamente grandes volumes de dados. Ele será o responsável por armazenar e indexar os dados enviados pelos Logstash, permitindo buscar estes dados praticamente em tempo real.
Seguem alguns conceitos importantes referente ao Elasticsearch:
- Index (índice): é como uma tabela de um banco de dados relacional. É uma coleção de documentos com características semelhantes. Por exemplo, podemos ter um índice para dados de clientes, outro para catálogo de produtos e outro para dados de pedidos. Um índice é identificado por um nome (com letras minúsculas) que é usado para se referir ao índice ao executar operações de indexação, pesquisa, atualização e exclusão de documentos.
- Type (tipo): Dentro de um índice você pode definir um ou mais tipos de documentos. Um tipo é uma categoria/partição lógica do seu índice. Em geral, um tipo é definido para documentos que possuem um conjunto de campos comuns. Por exemplo, vamos assumir que você possua uma plataforma de blogs e armazena todos os seus dados em um único índice. Neste índice você pode definir um tipo de dados de usuário, outro de postagens e outro de comentários, cada tipo com seus campos (fields) específicos.
- Document (documento): é uma unidade básica de informação que pode ser indexada. É como uma linha em uma tabela de um banco de dados relacional. Por exemplo, você pode ter um documento para um único cliente e outro para um único produto. Este documento é expresso em JSON. Dentro de um índice/tipo você pode armazenar quantos documentos desejar. Observe que, embora um documento resida fisicamente em um índice, ele é indexado/atribuído a um tipo dentro de um índice. Por exemplo, armazenei um novo "documento" no "tipo comentário" do "índice blog".
- Fields and Datatypes (campos e tipos de dados): um documento possui uma lista de campos. Um campo é como uma coluna em uma tabela de um banco de dados relacional. Cada campo pode armazenar um determinado tipo de dado que pode ser mapeado dinamicamente ou explicitamente.
- Index Templates (modelos de índice): permitem que você defina modelos de configuração e mapeamento que serão automaticamente aplicados quando novos índices forem criados.
Kibana → é uma plataforma de análise e visualização projetada para trabalhar com o Elasticsearch, além de permitir configurar e gerenciar todos os aspectos do Elastic Stack. Você usa o Kibana para pesquisar, visualizar e interagir com dados armazenados em índices Elasticsearch. Você pode facilmente realizar análises avançadas de dados e visualizá-las em uma variedade de gráficos, tabelas e mapas.
Utilizaremos o Kibana para visualizar as informações armazenadas e indexadas no Elasticsearch.
Pode-se observar na Figura 1 o fluxo da comunicação entre os mecanismos do Elastic Stack com os logs de acesso do Squid.
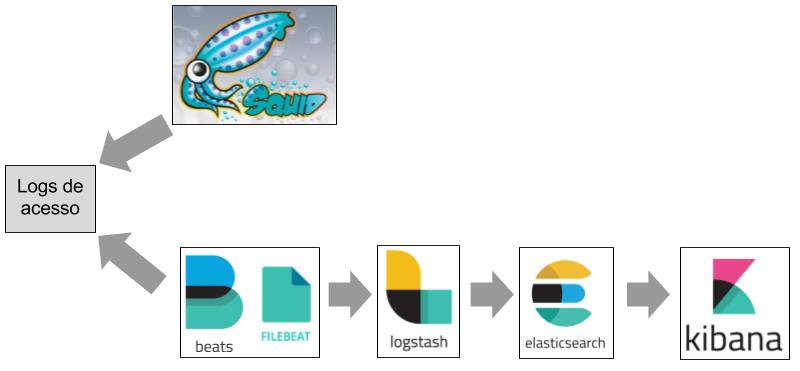
Figura 1
2. Preparando o ambiente
3. Subindo o Elastic Stack
4. Visualizando os logs no Kibana
Colocando Windows, Linux e Mac Os X em um mesmo PC
ArchLinux, uma distro de expressão aqui no VOL
fprint: Biometria livre, completa e total!
DrQueue + Blender = Render Farm para mortais
Thiago, já utilizo o ELK a um bom tempo, sabe me dizer se existe integração do Squid do Pfsense para o ELK?
Olá Anderson!
Não tenho muita experiência com pfSense, mas por ser um BSD acredito que seja possível instalar o Filebeat.
Encontrei dois artigos que podem te ajudar:
https://rareintel.com/2016/07/10/installing-logstash-filebeat-directly-pfsense-2-3/
https://extelligenceblog.it/2017/07/11/elastic-stack-suricata-idps-and-pfsense-firewall-part-1/
No último diz o seguinte:
Se você usa pfSense 2.3.4:
http://pkg.freebsd.org/freebsd:10:x86:64/latest/All/
Se você usa pfSense 2.4 (Released in October 2017):
http://pkg.freebsd.org/FreeBSD:11:amd64/latest/All/
O nome do pacote nestes repositórios é "beats-6.1.1_1.txz".
Outra possível solução seria usar o parâmetro "access_log" da configuração do Squid pra tentar enviar os logs diretamente ao Logstash ou para outro sistema via syslog que possua o Filebeat:
http://www.squid-cache.org/Doc/config/access_log/
Espero ter ajudado.
Abç!
[2] Comentário enviado por thiagodiniz em 18/01/2018 - 19:50h
Olá Anderson!
Não tenho muita experiência com pfSense, mas por ser um BSD acredito que seja possível instalar o Filebeat.
Encontrei dois artigos que podem te ajudar:
https://rareintel.com/2016/07/10/installing-logstash-filebeat-directly-pfsense-2-3/
https://extelligenceblog.it/2017/07/11/elastic-stack-suricata-idps-and-pfsense-firewall-part-1/
No último diz o seguinte:
Se você usa pfSense 2.3.4:
http://pkg.freebsd.org/freebsd:10:x86:64/latest/All/
Se você usa pfSense 2.4 (Released in October 2017):
http://pkg.freebsd.org/FreeBSD:11:amd64/latest/All/
O nome do pacote nestes repositórios é "beats-6.1.1_1.txz".
Outra possível solução seria usar o parâmetro "access_log" da configuração do Squid pra tentar enviar os logs diretamente ao Logstash ou para outro sistema via syslog que possua o Filebeat:
http://www.squid-cache.org/Doc/config/access_log/
Espero ter ajudado.
Abç!
Muito obrigado Thiago.
Vou testar tudo isso em um Lab.
Anderson,
Você não precisar instalar o filebeat, desde que você tenha o java instalado, basta baixar o .tar.gz, extrair e entrar na pasta do filebeat e executar ./filebeat e ele irá executar.
Att,
Patrocínio

Destaques
Artigos
File Browser: Crie sua Nuvem Pessoal Privada
A produção de áudio e vídeo no Linux e as distribuições dedicadas a esse fim
Criptografando sua Home com Gocryptfs para tristeza do meliante
A Involução do Linux e as Lambanças Desnecessárias desde o seu Lançamento
O Journal no Linux para a guarda e consulta de logs do sistema
Dicas
Otimizando o uso de Memória RAM no Ubuntu com zRAM
Usando alias no Terminal para comandos longos
Simplificando o manual do terminal no Ubuntu 26.04
Bloqueio da instalação e reinstalação do Snap (snapd) no Ubuntu
Tópicos
Continuando meus tópicos anteriores (12)
VoidBR - Void Linux adaptado ao Brasil. (0)
Top 10 do mês
-

Xerxes
1° lugar - 160.885 pts -

Fábio Berbert de Paula
2° lugar - 82.331 pts -

Alberto Federman Neto.
3° lugar - 45.934 pts -

Buckminster
4° lugar - 43.404 pts -

Alessandro de Oliveira Faria (A.K.A. CABELO)
5° lugar - 38.447 pts -

edps
6° lugar - 33.981 pts -

Mauricio Ferrari (LinuxProativo)
7° lugar - 26.181 pts -

Sidnei Serra
8° lugar - 25.977 pts -

Daniel Lara Souza
9° lugar - 24.147 pts -

Andre (pinduvoz)
10° lugar - 23.404 pts
Scripts
A maior comunidade GNU/Linux da América Latina! Artigos, dicas, tutoriais, fórum, scripts e muito mais. Ideal para quem busca auto-ajuda.
Site hospedado por: