Tutorial Kettle
O Kettle é uma ferramenta para integração de dados, responsável pelo processo de Extração, Transformação e Carga (ETL). Ferramentas ETL são utilizadas mais frequentemente em projetos de data warehouse, mas também podem ser utilizadas para outros propósitos, tais como migração de dados entre aplicações, exportação de banco para arquivos, limpeza de dados e na integração de aplicações.

Parte 2: Download e instalação
Sabendo-se então que o Kettle é uma ferramenta ETL, ou seja, ferramenta para fazer extração, tratamento e carga dos fatos e dimensões do DW. Podemos realizar o download da mesma no endereço:
Dependendo da plataforma de trabalho, deve-se selecionar o pacote adequado e descompactar o mesmo. Neste tutorial iremos tratar apenas para os sistemas operacionais Windows e Linux. Caso o OS seja Linux basta abrir o local onde foi descompactado o kettle e executar spoon.sh e no caso do Windows spoon.bat Isso tudo tomando os devidos cuidados com permissões de execução e escrita.
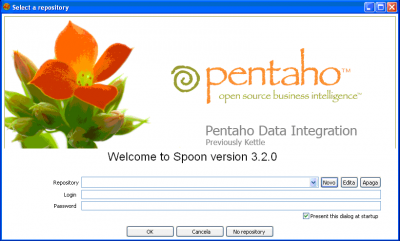
Figura 1 - Tela inicial
Para criar um novo repositório basta clicar em "Novo" e configurar uma conexão com a base de dados (figura 2).
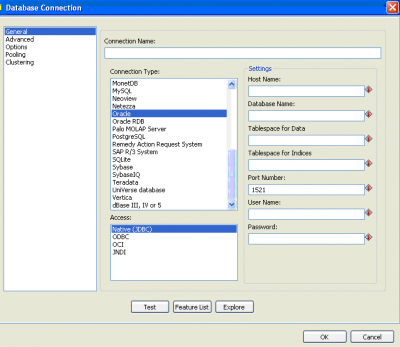
Figura 2 - Conexão com banco
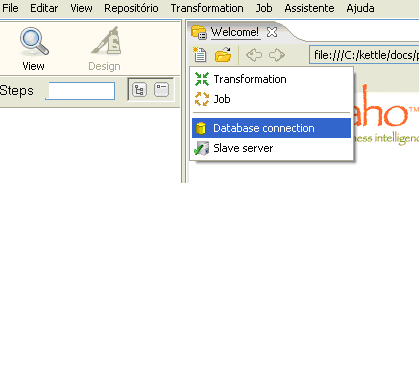
Figura 3 - Nova conexão
Dependendo da plataforma de trabalho, deve-se selecionar o pacote adequado e descompactar o mesmo. Neste tutorial iremos tratar apenas para os sistemas operacionais Windows e Linux. Caso o OS seja Linux basta abrir o local onde foi descompactado o kettle e executar spoon.sh e no caso do Windows spoon.bat Isso tudo tomando os devidos cuidados com permissões de execução e escrita.
Configurando um repositório
A figura 1 mostra a primeira tela apresentada na execução do Kettle. Nela existem duas opções: ou se configura um repositório onde ficarão armazenadas as Transformações e Jobs ou utiliza a ferramenta (No Repository) tendo que armazenar as Transformações e Jobs na máquina local.
Figura 1 - Tela inicial
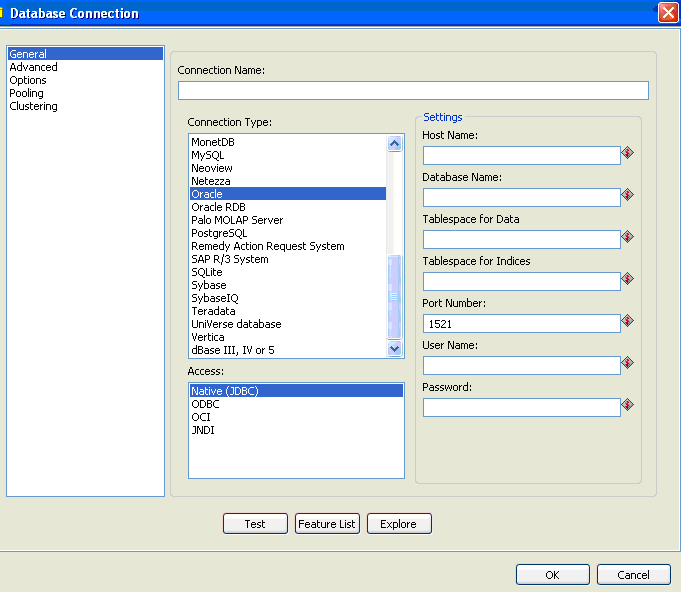
Figura 2 - Conexão com banco
Configurando conexão com banco
Na tela inicial do Kettle pode-se clicar em New > Database Connection (figura 3). Assim o sistema irá apresentar a tela da figura 2 onde se devem preencher os dados de acordo com o que for solicitado.
Figura 3 - Nova conexão
Gostaria de parabenizá-lo pelo artigo. Parece ser uma ferramenta interessante, dado que para BI, conheço somente ferramentas pagas, não caras, mas pagas. Mas, como comentário, ficou faltando somente esclarecer um pouco mais, dado que é uma ferramenta de ETL, sobre as suas bases : Granularidade, Dimensões, Fatos... Bom, mas ficou muito bom.
Parabéns
Abraços